Une Source of Truth (SoT) réseau, c’est l’intention modélisée une fois (sites, devices, IPAM, rôles), puis exposée aux outils et aux pipelines. NetBox est l’outil qui a fondé cette catégorie. La question pratique : j’ai un NetBox bien rempli, qu’est-ce que j’en fais demain matin pour automatiser mon réseau ?
Toute la série s’appuie sur le même petit lab, pour comparer ce qui est comparable : un fabric Spine/Leaf minimal réparti sur deux sites.
 Le lab de la série : 4 devices sur deux sites (PAR1 chez Acme, LON1 chez Globex), un patch panel dans le chemin de câblage de PAR1, des circuits entre les sites, un underlay BGP (AS 64512 et 64513) et un overlay en VRF CUSTOMER-A. C’est cette même architecture que chaque Source of Truth de la série va modéliser.
Le lab de la série : 4 devices sur deux sites (PAR1 chez Acme, LON1 chez Globex), un patch panel dans le chemin de câblage de PAR1, des circuits entre les sites, un underlay BGP (AS 64512 et 64513) et un overlay en VRF CUSTOMER-A. C’est cette même architecture que chaque Source of Truth de la série va modéliser.
NetBox modélise cette archi, et son API (REST, GraphQL, pynetbox) en fait une rampe d’automatisation. Les articles suivants reprennent la même infra avec Nautobot puis Infrahub, et un quatrième les compare et migre l’infra d’une SoT à l’autre avec infrahub-sync.
NetBox, l’origine de la lignée
NetBox naît en 2016 chez DigitalOcean, sous l’impulsion de Jeremy Stretch, pour un problème très concret : tenir l’inventaire d’un grand réseau sans tableur qui dérive. Il popularise l’idée d’Infrastructure Resource Modeling : modéliser les ressources dans une base unique qui fait autorité, en couvrant à la fois le DCIM (la vie physique du datacenter : sites, racks, devices, câbles) et l’IPAM (l’adressage : préfixes, IP, VRF, VLAN).
L’apport n’est pas la base de données, c’est le modèle. NetBox impose une façon de décrire un réseau qui se tient : un device a un type, un rôle, un site, un rack, des interfaces ; une IP appartient à un préfixe, parfois à un VRF. L’intention cesse de vivre dans des têtes et des fichiers épars, elle est posée une fois et devient consultable. C’est devenu le standard de facto de la SoT réseau, et le point de départ de presque toutes les démarches NetDevOps.
Un point à garder en tête pour la suite de la série : NetBox décrit, il n’agit pas de lui-même. Il sait dire « voici l’état voulu du réseau », pas « va configurer ce device ». C’est un parti pris de conception, et c’est lui qui ouvre la question de l’article suivant.
Ce que NetBox modélise
Sur le lab, NetBox 4.6.2 décrit un petit fabric Spine/Leaf : 4 devices, 10 interfaces, 4 front ports et 4 rear ports, 2 câbles, 2 racks, 3 types de device, 2 plateformes, 2 VLAN, 1 VRF, 4 préfixes, 3 IP et 2 circuits. Petit, mais représentatif : on y retrouve toutes les briques d’un vrai inventaire.
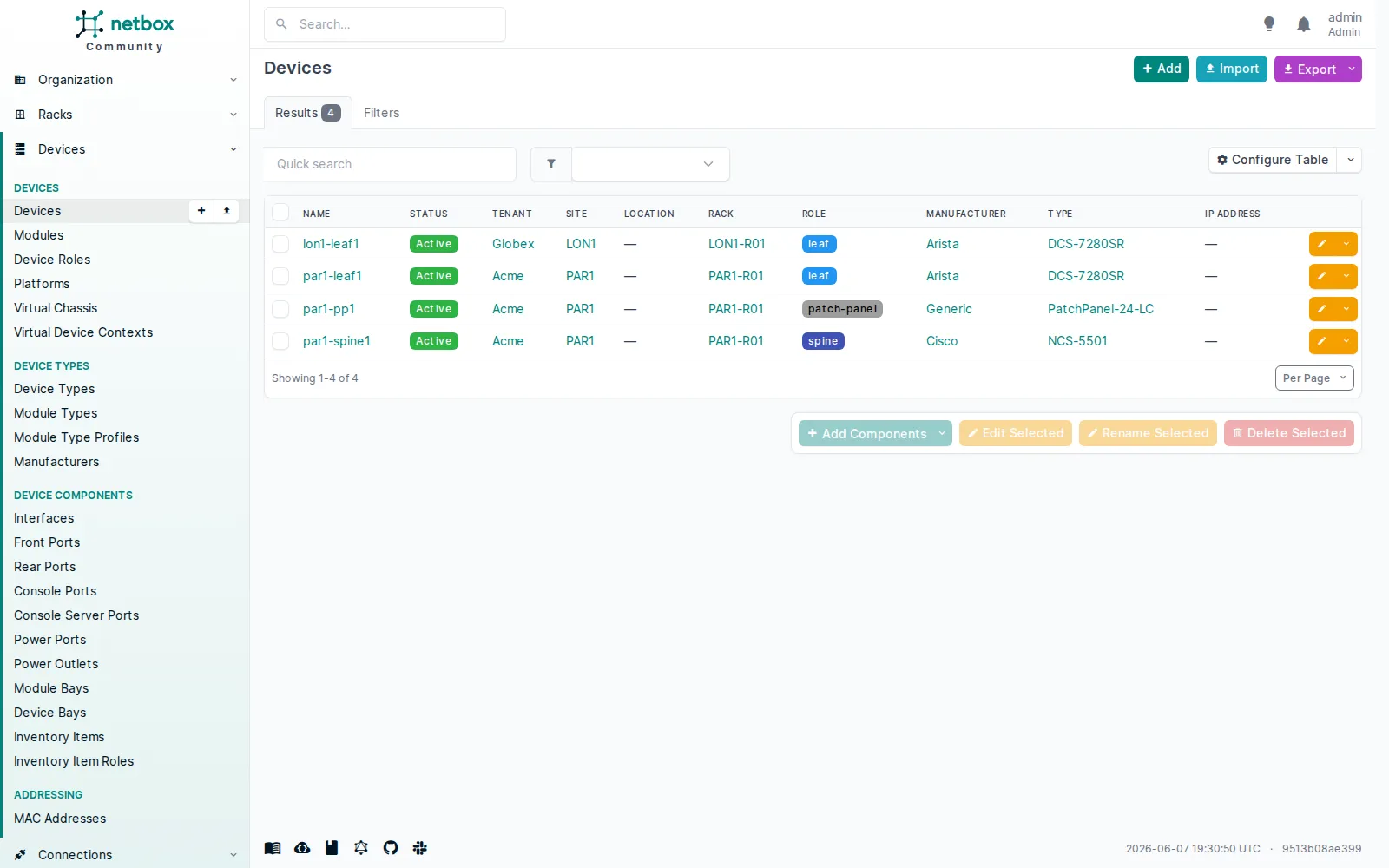 Les 4 devices du lab :
Les 4 devices du lab : lon1-leaf1 (tenant Globex, site LON1), et par1-leaf1, par1-pp1, par1-spine1 (tenant Acme, site PAR1). Tous au statut Active. Les colonnes Location et IP Address sont vides ici.
La liste se lit comme une fiche d’inventaire : chaque ligne porte le constructeur (Arista, Cisco, Generic), le type (DCS-7280SR, NCS-5501, PatchPanel-24-LC), le rack, et le tenant, c’est à dire le client ou l’entité à qui appartient l’équipement. Toute la modélisation DCIM est là, derrière ces colonnes.
Côté IPAM, le même principe : l’adressage est structuré, pas listé à plat.
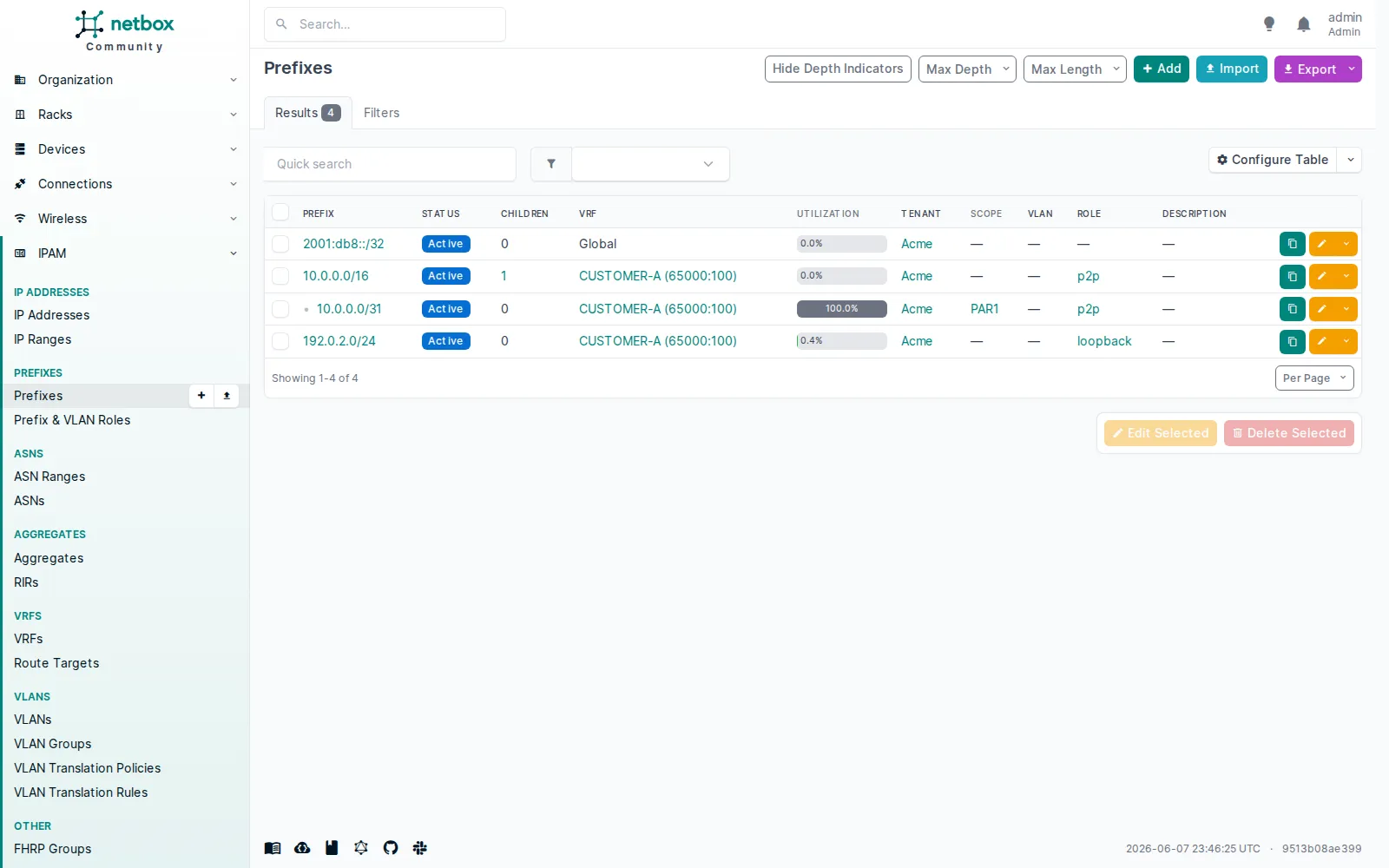 L’IPAM de NetBox : 4 préfixes, dont un IPv6 (
L’IPAM de NetBox : 4 préfixes, dont un IPv6 (2001:db8::/32) et des /31 de point-à-point. Chaque IP du lab se rattache à l’un d’eux.
Les choix de modèle qui comptent
NetBox a fait des choix de modélisation précis. Ils sont invisibles tant qu’on reste dans l’UI, mais ils déterminent tout dès qu’on automatise ou qu’on migre. Quatre méritent d’être nommés, parce qu’ils reviendront dans les articles suivants.
Le statut est un choix inline, pas un objet. Le statut d’un device (active) est une valeur de liste attachée à l’objet, pas une entité indépendante. On le verra noir sur blanc dans l’API plus bas : status y est un petit dictionnaire {"value": "active", "label": "Active"}, pas une référence vers un objet Statut.
Les rôles vivent sur trois endpoints distincts. NetBox sépare le rôle d’un device, le rôle d’un rack et le rôle IPAM. Ce sont trois pages, et trois endpoints d’API différents (dcim/device-roles, dcim/rack-roles, ipam/roles).
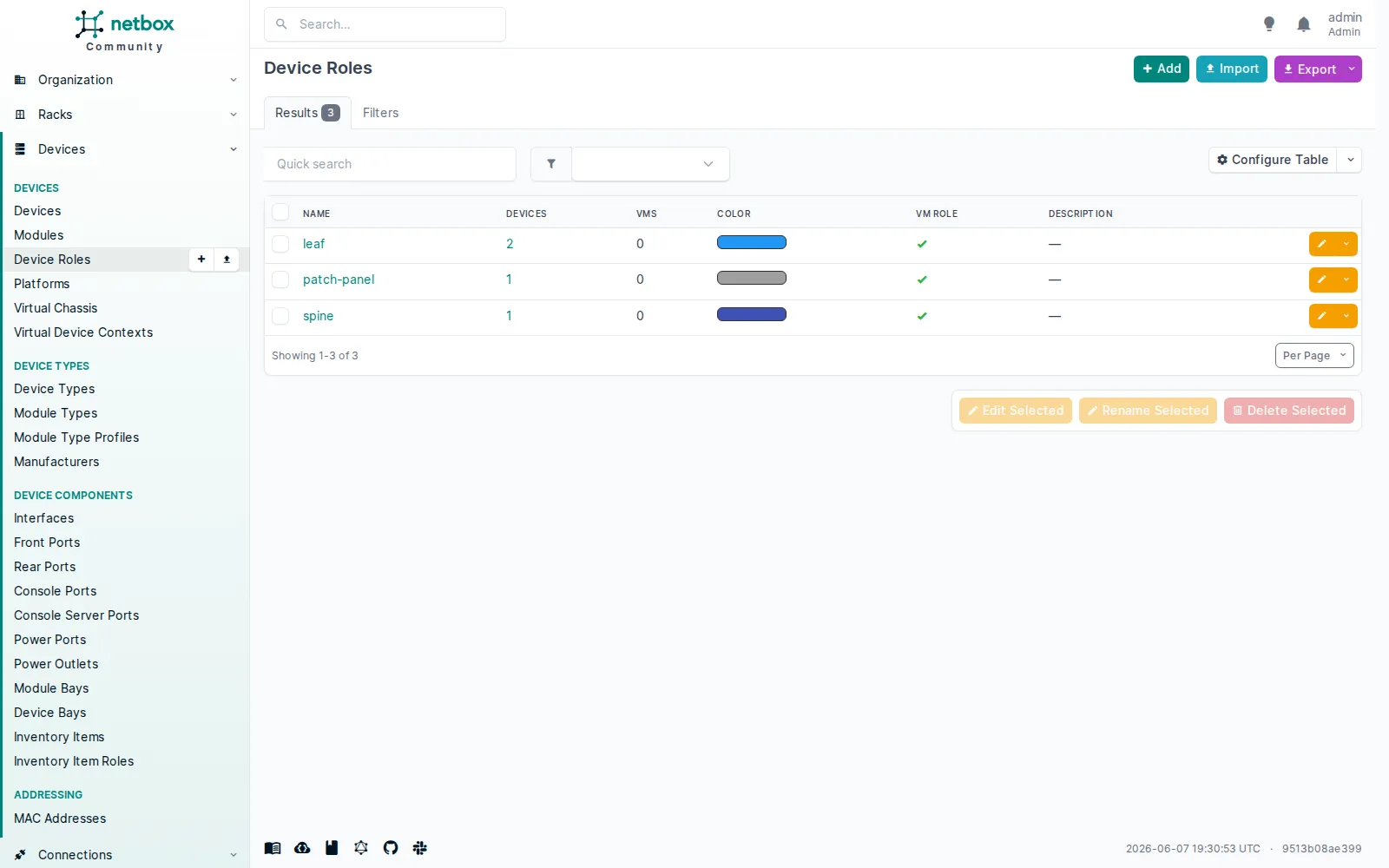 Le premier des trois endpoints de rôles :
Le premier des trois endpoints de rôles : dcim/device-roles (leaf, patch-panel, spine). Les rôles de rack (compute) et d’IPAM (loopback, p2p) vivent sur deux autres pages.
Les identifiants sont des entiers auto-incrémentés. Chaque objet a un id entier, attribué par table. C’est commode et lisible, mais cela signifie qu’un tenant et un manufacturer peuvent tous deux porter l’id = 1. Tant qu’on reste dans NetBox, aucun souci ; le jour d’une migration, c’est un piège (j’y reviens au moment de la migration).
Il n’y a pas de notion de namespace IPAM. Un VRF NetBox se décrit par son nom, son RD et son tenant, point.
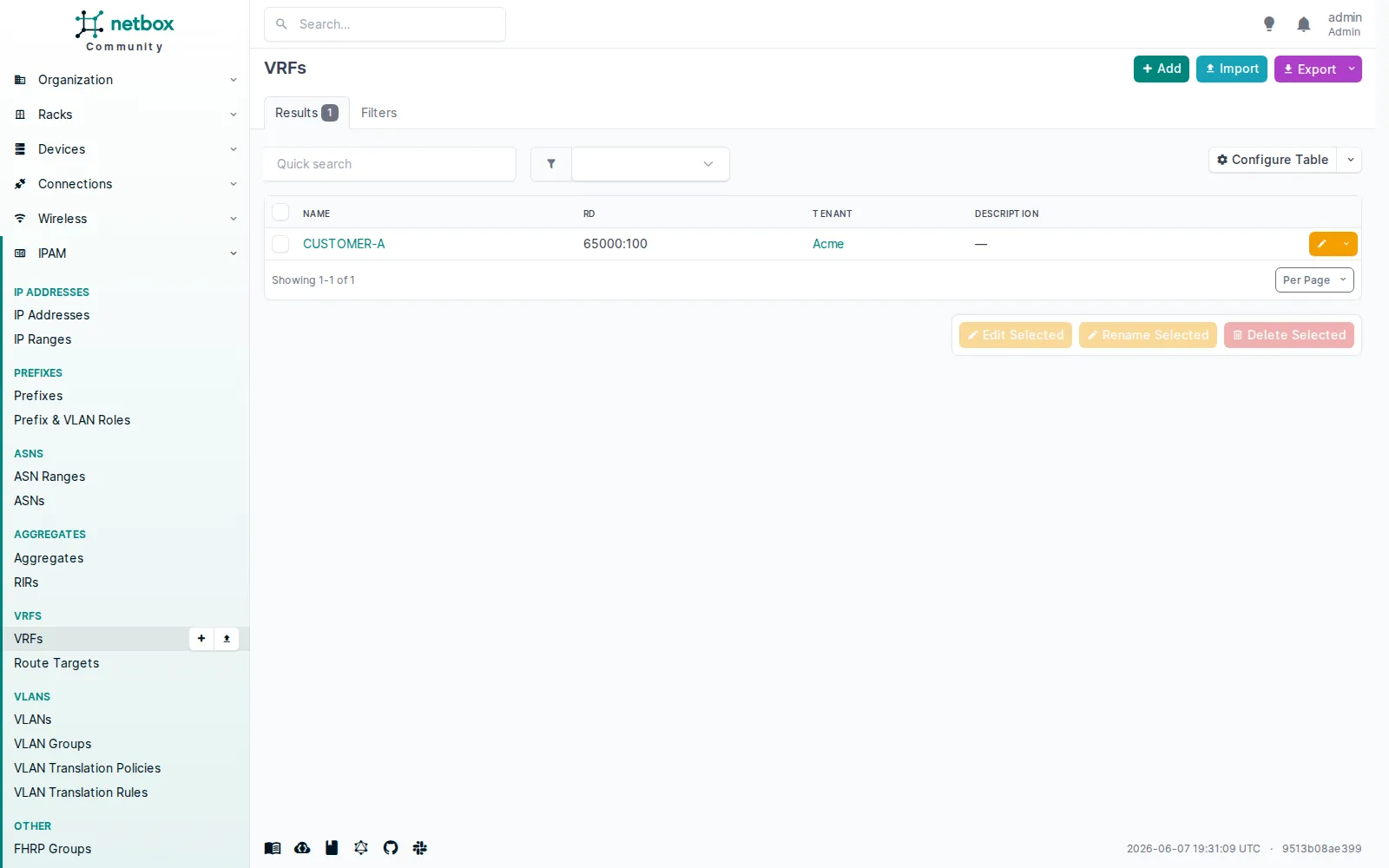 Le VRF
Le VRF CUSTOMER-A (RD 65000:100) : pas de colonne Namespace. NetBox ne modélise pas cette notion, et c’est un contraste direct avec Nautobot, qu’on verra à l’article Nautobot.
Pris isolément, chacun de ces choix se défend : ce sont les conventions de NetBox, cohérentes entre elles. Ce sont aussi les lignes le long desquelles les autres SoT divergent, et donc ce qui décide de la difficulté d’une migration.
L’intention au-delà du modèle : custom fields et config context
Le modèle de base couvre l’attendu : devices, interfaces, IPAM. Mais la vraie intention déborde toujours du cadre : un niveau de criticité métier, un identifiant de supervision, des paramètres SNMP, NTP, BGP. NetBox, fidèle à son rôle de référentiel, offre deux mécanismes pour modéliser cette traîne sans forker le schéma. C’est cette traîne, criticité et config context, qu’un pipeline vient lire au même endroit que le reste de l’inventaire.
Les custom fields ajoutent vos propres champs typés à n’importe quel objet. Sur le lab, par1-leaf1 porte un criticality (une liste de choix, ici High) et un monitoring_id (du texte, MON-001). Stockés, éditables, exposés dans l’API sous custom_fields.
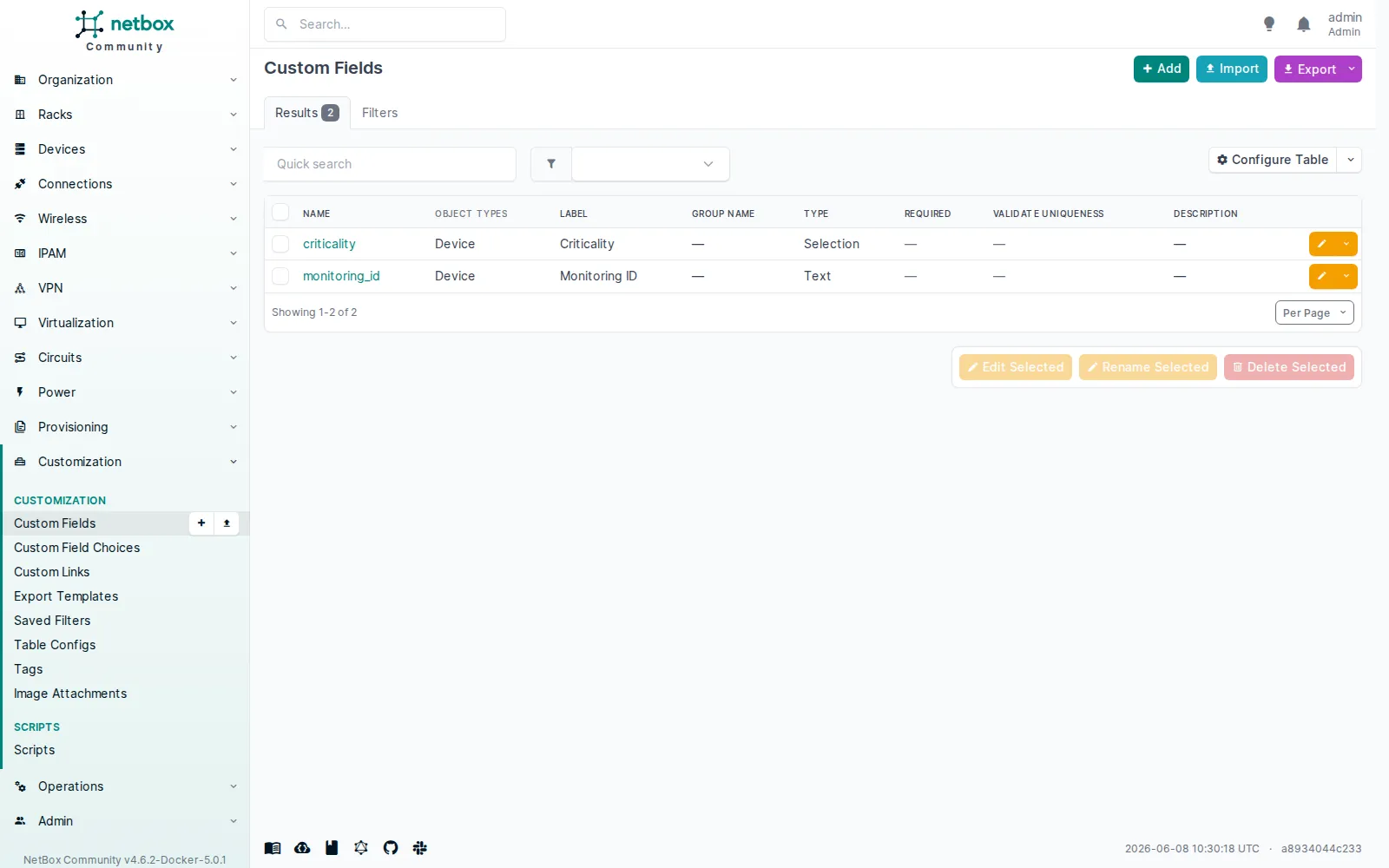 Deux champs personnalisés définis sur l’objet Device :
Deux champs personnalisés définis sur l’objet Device : criticality (Selection) et monitoring_id (Text). Ils s’éditent comme n’importe quel attribut et sortent dans l’API sous custom_fields.
Le config context est de l’intention JSON affectée par critères (site, rôle, plateforme, tenant) et fusionnée par device. C’est là qu’on range SNMP, NTP, BGP, AAA, tout ce qui alimente les templates sans mériter un modèle dédié. NetBox montre la mécanique de fusion de façon limpide : un contexte source baseline (SNMP et NTP), un override local sur le device (le BGP), et le rendu mergé des deux.
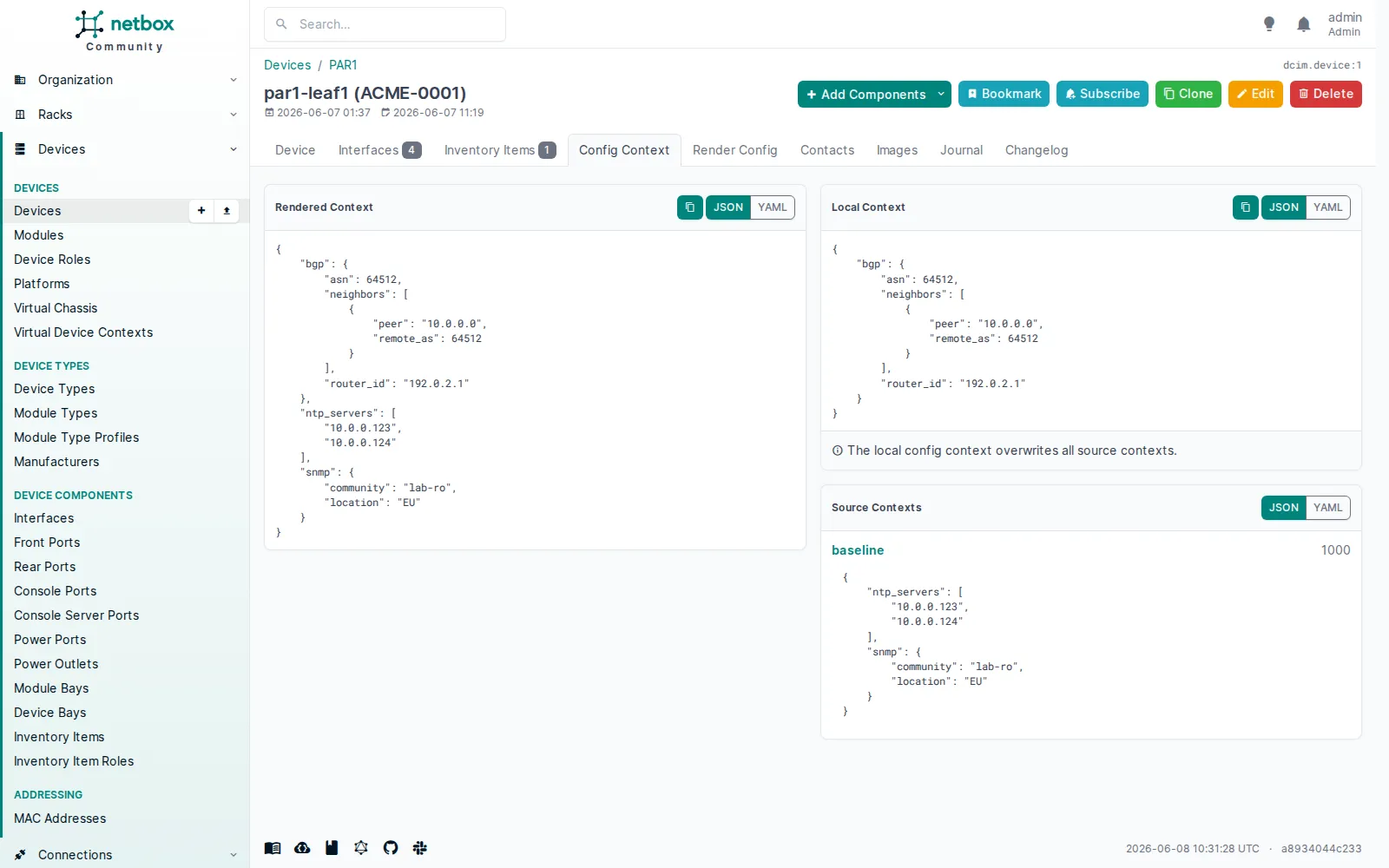 L’onglet Config Context met côte à côte le Rendered Context (le merge : bgp + ntp_servers + snmp), le Local Context du device (le seul
L’onglet Config Context met côte à côte le Rendered Context (le merge : bgp + ntp_servers + snmp), le Local Context du device (le seul bgp, qui « overwrites all source contexts »), et le Source Context baseline (poids 1000, snmp + ntp). NetBox rend le merge nativement.
Custom fields et config context complètent le modèle de base : ils portent l’intention qui n’entre pas dans les cases prévues, et que les pipelines viennent lire au même endroit que le reste du référentiel.
Étendre NetBox : les plugins
Au-delà des champs et du config context, NetBox se laisse étendre par un système de plugins : un catalogue est intégré, et chaque plugin ajoute ses propres modèles ou vues. Le lab n’en installe aucun, mais le mécanisme existe et se gère depuis cette page.
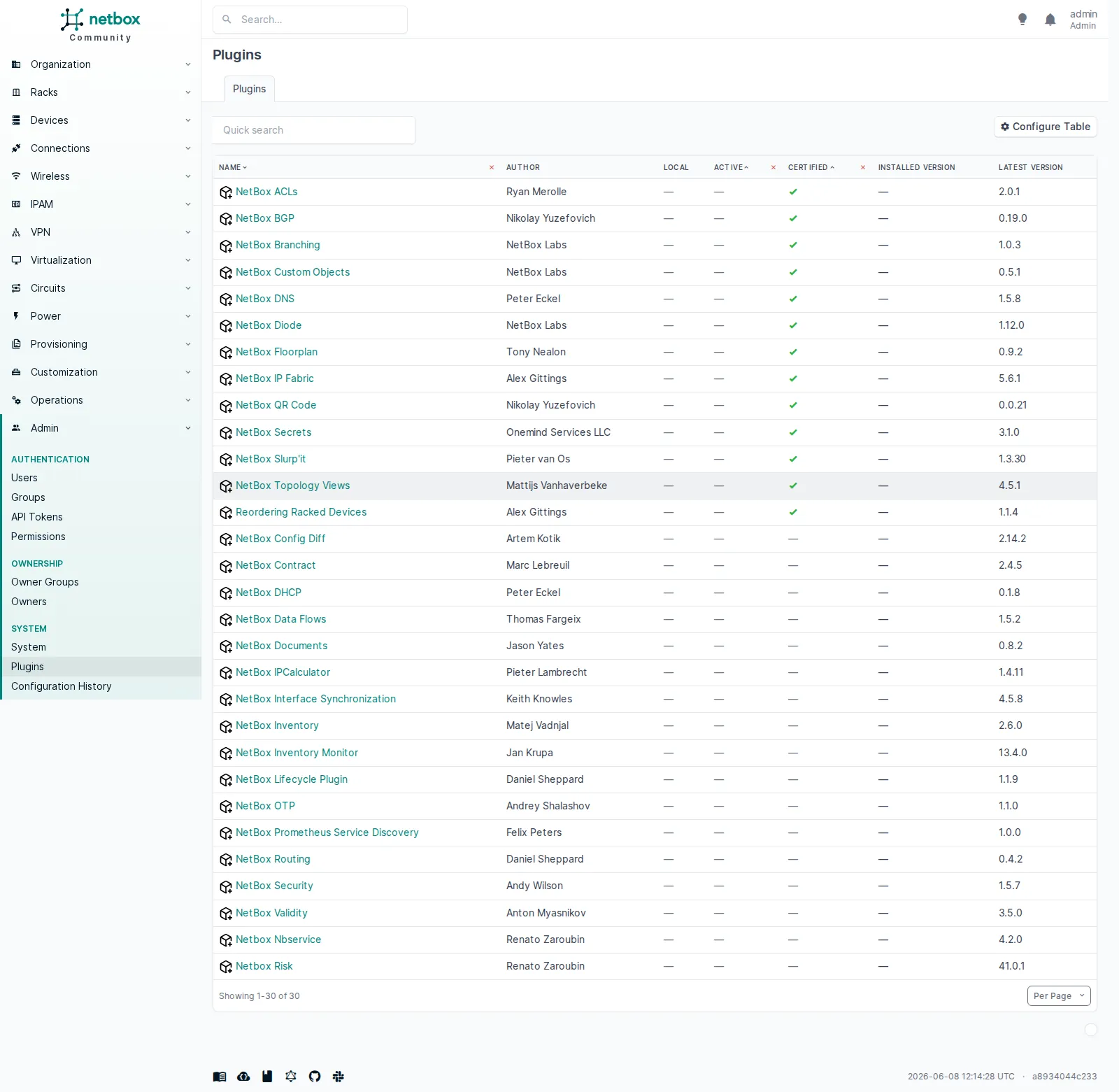 La page Plugins de NetBox : un catalogue de 30 plugins (colonnes NAME, AUTHOR, LOCAL, ACTIVE, CERTIFIED, INSTALLED VERSION, LATEST VERSION), tous avec INSTALLED VERSION vide, aucun installé dans ce lab. Le catalogue contient même un plugin
La page Plugins de NetBox : un catalogue de 30 plugins (colonnes NAME, AUTHOR, LOCAL, ACTIVE, CERTIFIED, INSTALLED VERSION, LATEST VERSION), tous avec INSTALLED VERSION vide, aucun installé dans ce lab. Le catalogue contient même un plugin NetBox BGP, qu’on n’utilise pas ici : le BGP du lab vit en config context.
L’API, la porte d’entrée de l’automatisation
Tout ce modèle ne sert l’automatisation que parce qu’il est adressable. NetBox expose la totalité de son inventaire par une API REST, une API GraphQL, et un client Python officiel (pynetbox). C’est par là que les pipelines lisent l’intention. Les extraits ci-dessous sont des sorties réelles, exécutées en lecture seule sur le lab et capturées telles quelles.
En REST, un simple GET sur l’endpoint des devices renvoie l’inventaire en JSON :
curl -s -H "Authorization: Token <token>" \
"http://localhost:8000/api/dcim/devices/?limit=2" | python3 -m json.tool
{
"count": 4,
"results": [
{
"id": 3,
"name": "lon1-leaf1",
"device_type": { "model": "DCS-7280SR", "manufacturer": { "name": "Arista" } },
"role": { "name": "leaf", "slug": "leaf" },
"site": { "name": "LON1", "slug": "lon1" },
"status": { "value": "active", "label": "Active" }
}
]
}
La réponse (tronquée ici) dit l’essentiel sur le modèle : l’id est un entier (3), le status est un dictionnaire inline ({"value": "active", ...}), et les objets liés (type, rôle, site) sont imbriqués. C’est la forme brute de l’intention, prête à alimenter un template ou un script.
Le client Python pynetbox enveloppe cette API dans des objets confortables :
>>> import pynetbox
>>> nb = pynetbox.api("http://localhost:8000", token=TOKEN)
>>> nb.dcim.devices.count()
4
>>> d = nb.dcim.devices.get(name="par1-leaf1"); d.id, str(d), d.device_type.model, str(d.site)
1 | par1-leaf1 | DCS-7280SR | PAR1
>>> [str(x) for x in nb.dcim.devices.all()]
['lon1-leaf1', 'par1-leaf1', 'par1-pp1', 'par1-spine1']
Quatre devices, interrogés par nom ou listés en une ligne. Noter au passage que par1-leaf1 porte l’id = 1, là où lon1-leaf1 avait l’id = 3 : les entiers sont attribués dans l’ordre de création, pas par site.
Enfin, NetBox embarque un explorer GraphQL (GraphiQL), pour requêter exactement les champs voulus, sans sur-récupérer.
 NetBox embarque GraphiQL : on interroge l’intention directement depuis le navigateur, en ne demandant que les champs utiles.
NetBox embarque GraphiQL : on interroge l’intention directement depuis le navigateur, en ne demandant que les champs utiles.
La même question (les devices, leur statut, leur rôle, leur site, leur modèle), posée en GraphQL :
{
device_list {
id
name
status
role { name }
site { name }
device_type { model }
}
}
{
"data": {
"device_list": [
{
"id": "3",
"name": "lon1-leaf1",
"status": "active",
"role": { "name": "leaf" },
"site": { "name": "LON1" },
"device_type": { "model": "DCS-7280SR" }
},
{
"id": "1",
"name": "par1-leaf1",
"status": "active",
"role": { "name": "leaf" },
"site": { "name": "PAR1" },
"device_type": { "model": "DCS-7280SR" }
}
]
}
}
Détail révélateur : en GraphQL, status ressort comme un scalaire ("active") là où le REST renvoyait un dictionnaire. Deux portes sur la même donnée, deux formes. Pour un pipeline, GraphQL a l’avantage de cadrer la réponse à ce dont on a besoin.
Et concrètement, je fais quoi ?
NetBox lu par l’API, c’est l’intention disponible pour des outils. Voici quelques pistes d’automatisation que cet inventaire amorce. Ce sont des directions, pas des manips faites sur ce lab : à chaque fois, l’entrée est un objet NetBox, la sortie un effet concret.
- Générer la configuration. Un template Jinja alimenté par l’API (rôle du device, interfaces, IP, VRF) produit une config cohérente avec l’intention. NetBox décrit, le template rend.
- Alimenter la supervision et le DNS. L’inventaire de devices et d’IP devient la source qui peuple un outil de monitoring ou une zone DNS, au lieu d’une saisie manuelle qui se désynchronise.
- Vérifier la conformité. On compare l’état réel récupéré sur les équipements à l’intention NetBox, et on signale les écarts. La SoT devient la référence du « ce qui devrait être ».
- Piloter l’IPAM par script. Réserver un préfixe, allouer la prochaine IP libre : pynetbox expose tout cela, ce qui évite les collisions d’adressage gérées « à la main ».
Le point commun de ces pistes : la logique d’automatisation vit à l’extérieur de NetBox, dans un script, un pipeline, un orchestrateur. NetBox fournit la donnée, un autre outil agit.
NetBox décrit, il n’agit pas
C’est la limite de conception, et le pont vers l’article Nautobot. NetBox propose bien des webhooks et des event rules pour réagir à un changement, mais son cœur reste descriptif : il tient l’intention, il ne l’exécute pas. L’automatisation est donc toujours pilotée du dehors, ce qui marche très bien, mais peut devenir lent et fragile à grande échelle, quand un orchestrateur externe interroge la SoT en boucle.
D’où la question que pose Nautobot : et si on rapprochait la logique d’automatisation de la donnée, jusqu’à la faire tourner dans la Source of Truth ? C’est le sujet de l’article suivant.
À retenir
- NetBox a fondé la SoT réseau en imposant un modèle (DCIM + IPAM) qui fixe l’intention une fois et l’empêche de dériver.
- Le modèle a des choix précis : statut inline, rôles éclatés sur trois endpoints, identifiants entiers, pas de namespace IPAM. Invisibles à l’usage, structurants dès qu’on automatise ou qu’on migre.
- L’API est la vraie porte d’entrée : REST, GraphQL et pynetbox rendent l’inventaire adressable, et c’est ce qui en fait une rampe d’automatisation.
- NetBox décrit, il n’agit pas nativement : l’automatisation reste externe. C’est exactement ce que l’article Nautobot vient déplacer.
Pour aller plus loin
- Le pourquoi d’une SoT, en plus court : Démarrer en NetDevOps.
- La suite de la série : Nautobot, mettre l’automatisation dans la Source of Truth.
Dépôt du projet : netbox-community/netbox