Nautobot est une Source of Truth (SoT) réseau née d’un fork de NetBox, qui a ensuite divergé sur deux points : un modèle de données plus strict, et la possibilité de faire tourner l’automatisation dans la SoT plutôt que de la piloter de l’extérieur. Cet article montre comment Nautobot modélise une infra réseau, et ce que ces choix changent en pratique.
Toute la série s’appuie sur le même petit lab, pour comparer ce qui est comparable : un fabric Spine/Leaf minimal réparti sur deux sites.
 Le lab de la série : 4 devices sur deux sites (PAR1 chez Acme, LON1 chez Globex), un patch panel dans le chemin de câblage de PAR1, des circuits entre les sites, un underlay BGP (AS 64512 et 64513) et un overlay en VRF CUSTOMER-A. C’est cette même architecture que chaque Source of Truth de la série va modéliser.
Le lab de la série : 4 devices sur deux sites (PAR1 chez Acme, LON1 chez Globex), un patch panel dans le chemin de câblage de PAR1, des circuits entre les sites, un underlay BGP (AS 64512 et 64513) et un overlay en VRF CUSTOMER-A. C’est cette même architecture que chaque Source of Truth de la série va modéliser.
Deuxième article de la série Source of Truth : la même architecture, cette fois modélisée par Nautobot. NetBox et Infrahub la modélisent dans les autres articles, et un quatrième compare les trois et migre l’infra avec infrahub-sync.
Un fork de NetBox qui a divergé
Nautobot est un fork de NetBox, lancé par Network to Code en 2021. Au départ, le même ADN : DCIM, IPAM, le même vocabulaire d’inventaire. Puis la divergence, qui n’est pas qu’une question de fonctionnalités en plus. Nautobot a ré-architecturé son modèle de données (le modèle dit « v2 ») et, surtout, il a fait un pari différent sur la place de l’automatisation.
Réduire Nautobot à « NetBox plus des Jobs » serait donc faux. Les deux outils partagent une origine, mais le modèle, lui, a été repensé sur plusieurs points qui comptent en pratique. On les voit directement sur le lab.
La thèse de Nautobot : l’automatisation au plus près de la donnée
L’idée centrale tient en une phrase : au lieu de piloter une SoT passive depuis l’extérieur, on exécute la logique d’automatisation à l’intérieur de la SoT. Concrètement, ce sont les Jobs : du code Python qui tourne dans Nautobot, avec un accès direct à la base via l’ORM Django, ses logs, ses permissions et sa planification.
Concrètement, un Job qui itère l’inventaire lit la donnée là où elle est, sans enchaîner des dizaines d’allers-retours HTTP vers une API distante. La SoT n’est plus seulement une base qu’on interroge, c’est aussi un endroit où l’on agit. On y revient plus bas, avec un Job exécuté pour de vrai.
Le modèle v2 : statuts, rôles et identifiants repensés
La première chose que change Nautobot, c’est la solidité du modèle. Trois exemples, tous visibles sur le lab.
Le statut est un objet de première classe. Là où NetBox stockait active comme une valeur inline, Nautobot en fait une entité dédiée, typée par contenu : un statut sait à quels types d’objets il s’applique (circuits, devices, interfaces…).
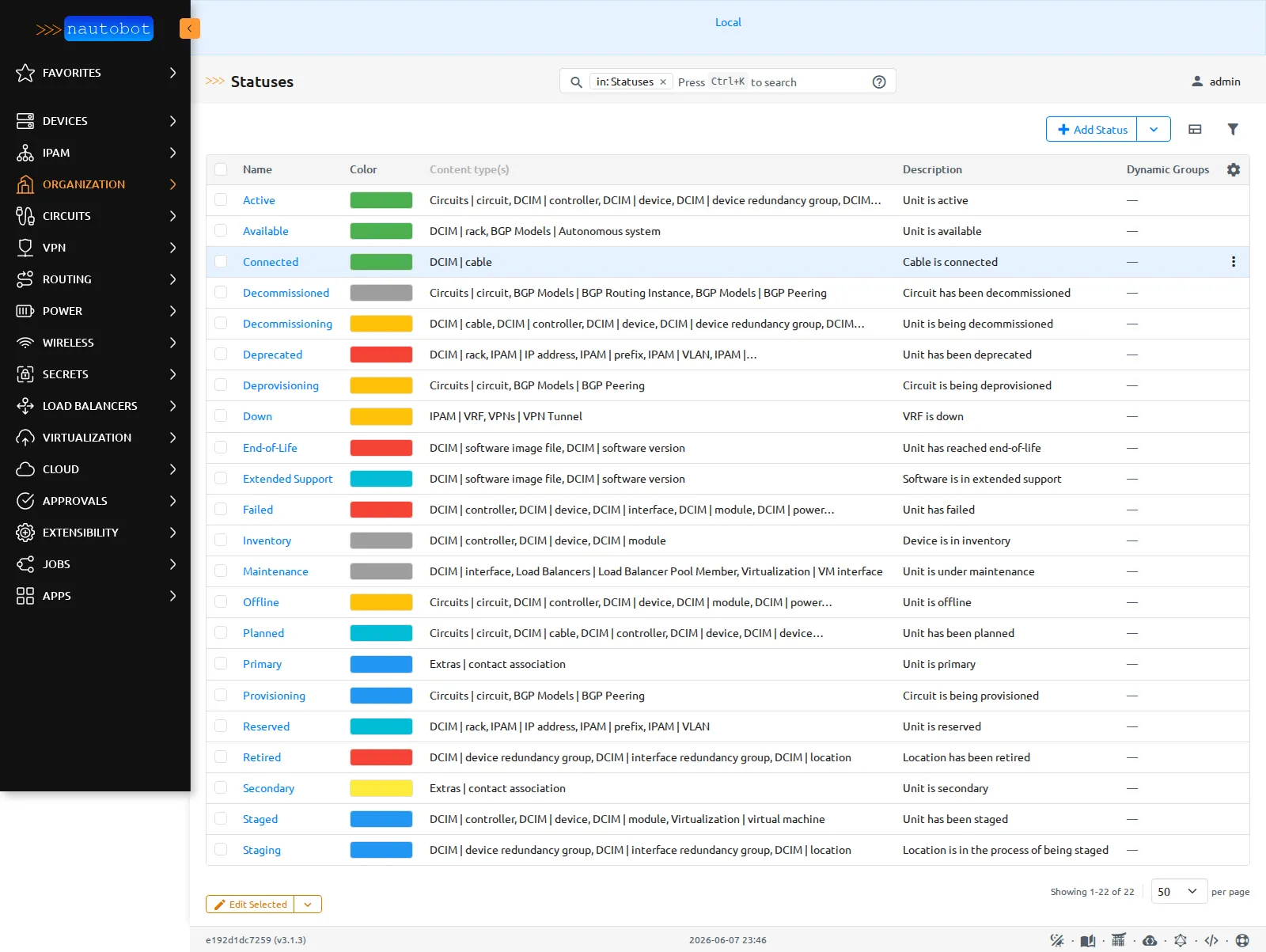 Les statuts sont des objets dédiés, typés par contenu (Circuits, DCIM device, IPAM…). Côté NetBox, le statut n’était qu’une valeur de liste attachée à l’objet.
Les statuts sont des objets dédiés, typés par contenu (Circuits, DCIM device, IPAM…). Côté NetBox, le statut n’était qu’une valeur de liste attachée à l’objet.
Les rôles tiennent dans une seule table. NetBox éclatait les rôles sur trois endpoints (device, rack, IPAM). Nautobot les unifie dans une table unique, où chaque rôle déclare les types d’objets auxquels il s’applique.
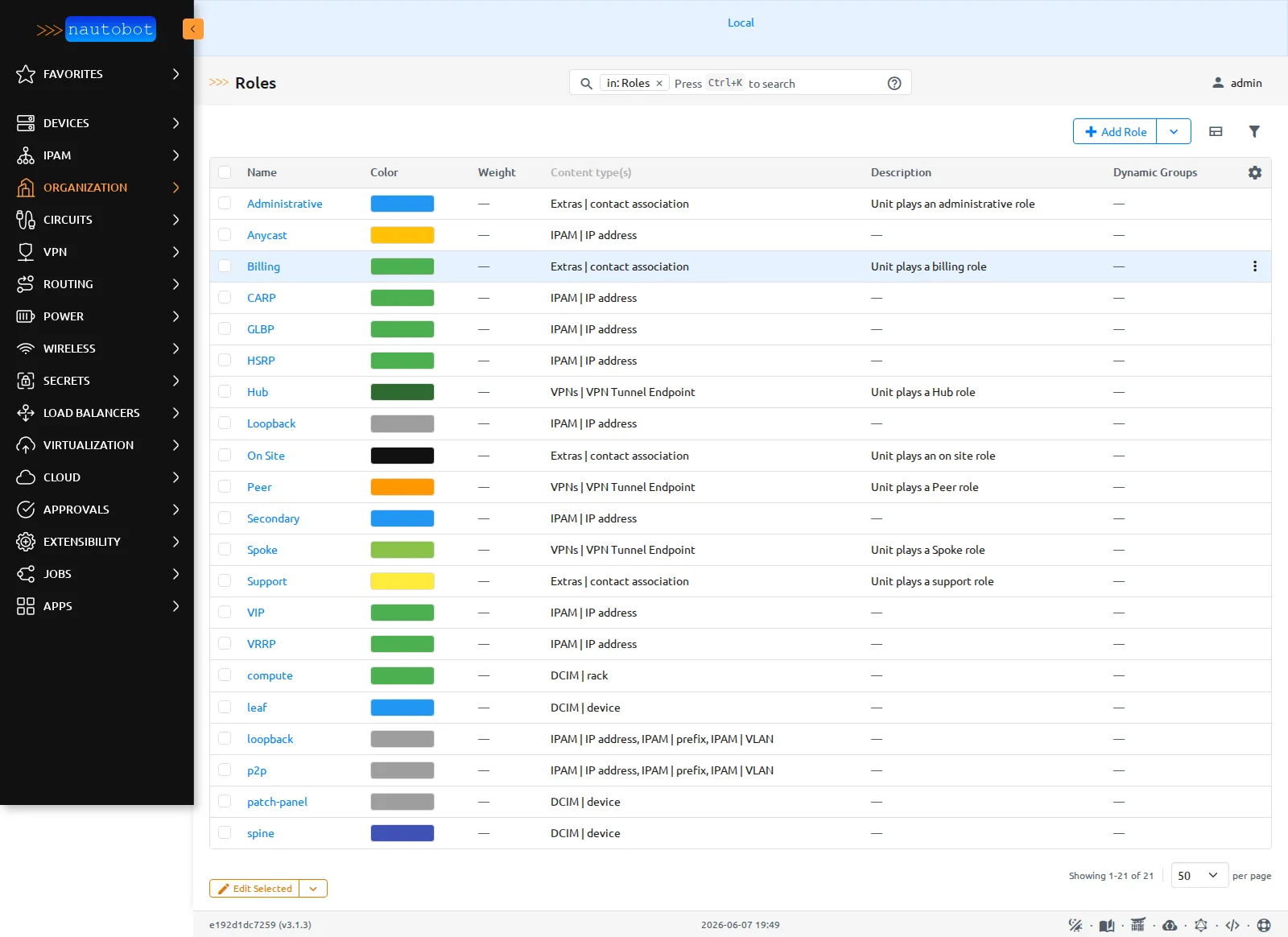 Une seule table de rôles (21 entrées), typée par Content type(s) :
Une seule table de rôles (21 entrées), typée par Content type(s) : leaf, spine, patch-panel pour les devices (DCIM | device), compute pour les racks, loopback et p2p pour l’IPAM. NetBox demandait trois endpoints distincts.
Les identifiants sont des UUID. Chaque objet Nautobot est identifié par un UUID, pas par un entier auto-incrémenté.
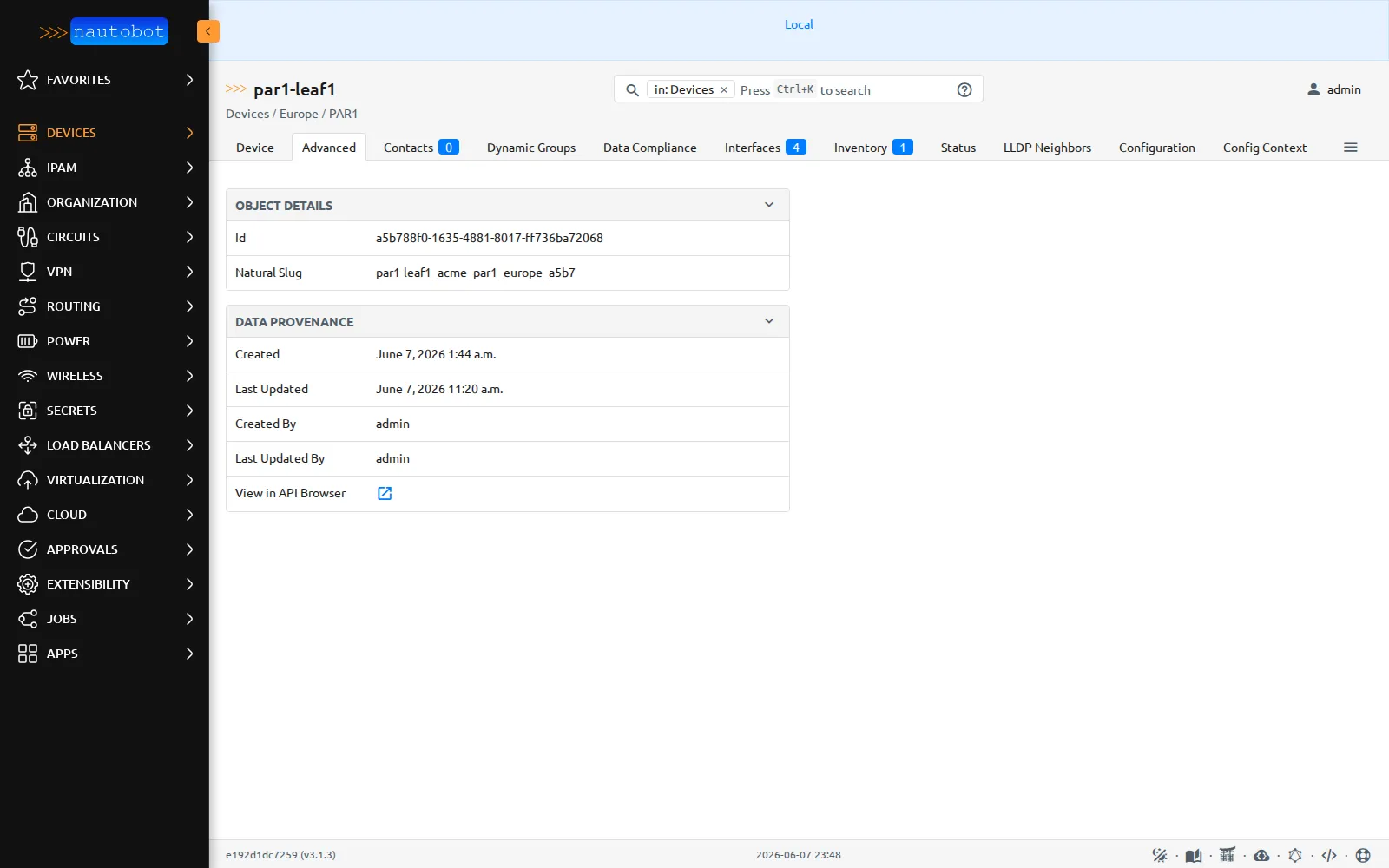 L’identifiant de
L’identifiant de par1-leaf1 est un UUID (a5b788f0-...). Le même device, côté NetBox, portait l’id = 1 entier. Ce détail paraît anodin ; il évite les collisions d’identifiants entre familles d’objets, et il jouera un rôle au moment d’une migration.
Dernier point de modèle, plus discret : les emplacements. Nautobot remplace le couple rigide régions + sites de NetBox par des locations typées et hiérarchiques.
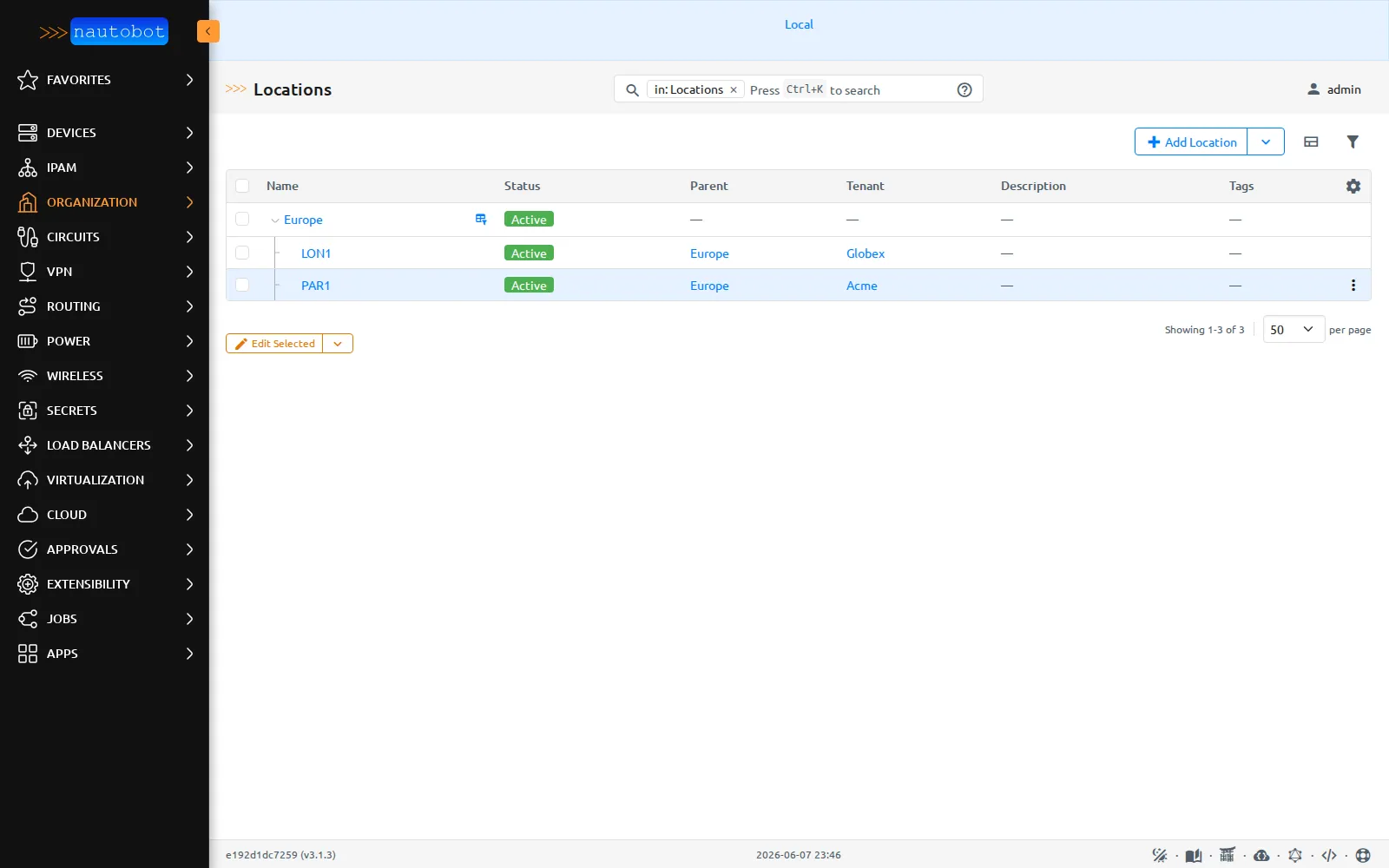 Les locations sont hiérarchiques (
Les locations sont hiérarchiques (LON1 et PAR1 sous Europe) et reposent sur des location-types. Plus souple que le couple régions + sites figé de NetBox.
Namespaces : l’IPAM multi-tenant
Le changement de modèle le plus parlant pour l’IPAM, c’est le namespace. Un VRF Nautobot vit dans un namespace, et l’adressage est isolé namespace par namespace.
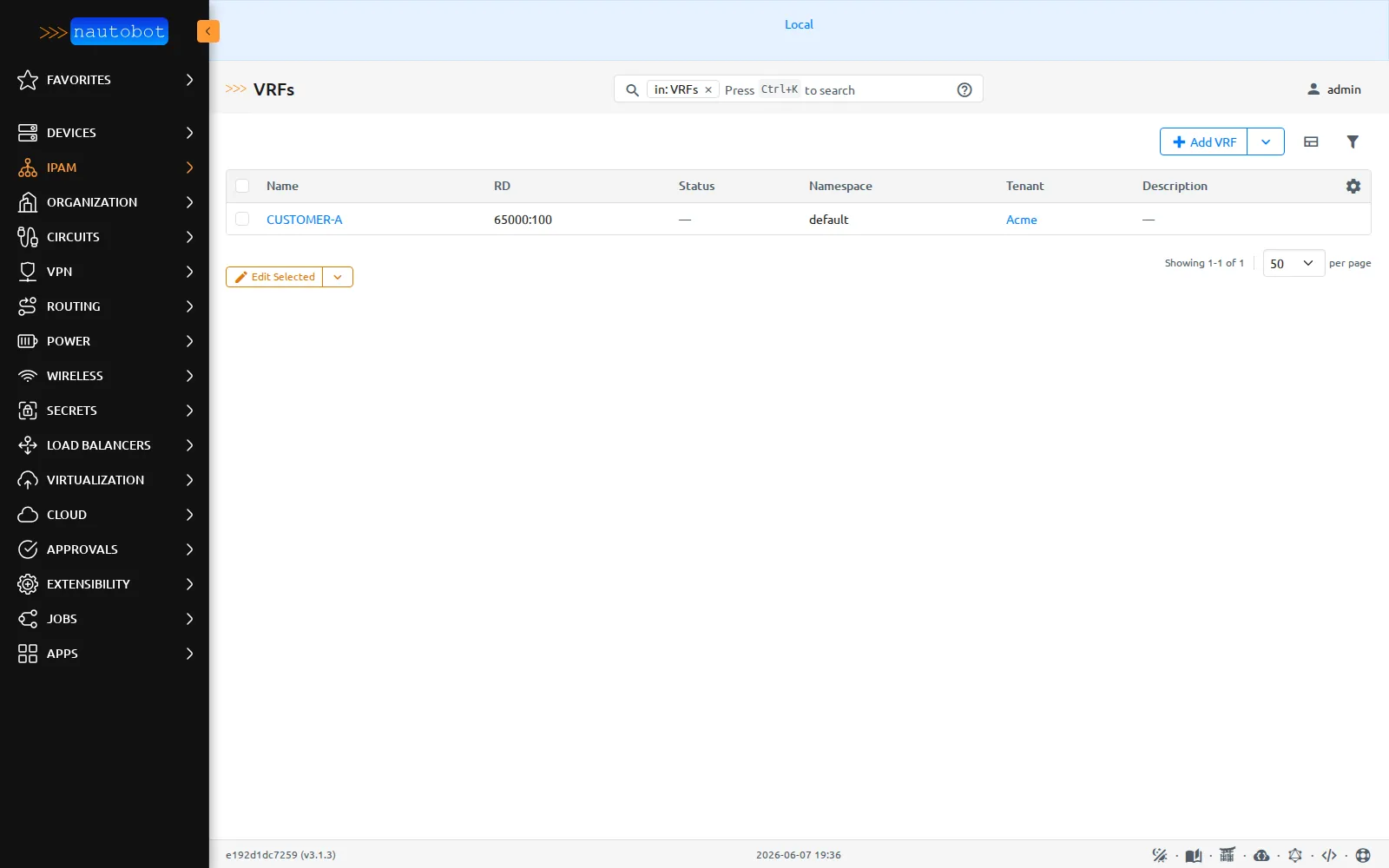 Le VRF
Le VRF CUSTOMER-A porte une colonne Namespace (default). C’est exactement la notion que NetBox n’avait pas.
À quoi ça sert ? Au cas multi-tenant avec adressage qui se recoupe. Deux clients qui utilisent tous les deux 10.0.0.0/24 sans collision : impossible à modéliser proprement sans une frontière qui sépare leurs plans d’adressage. Les namespaces fournissent cette frontière.
Est-ce « mieux » que NetBox ? C’est un avis, pas une vérité : si l’on n’a jamais d’IP qui se recoupent, le namespace ajoute de la complexité pour rien, et l’IPAM de NetBox a ses propres évolutions. Mais le jour où l’on a réellement besoin d’isoler des plans d’adressage qui se chevauchent, c’est parfois un meilleur choix, et c’est surtout un modèle plus explicite.
Les apps étendent le modèle
Nautobot se laisse étendre par des apps (anciennement plugins) qui ajoutent de vrais modèles, pas seulement des champs. L’exemple du lab est l’app BGP Models, qui modélise le BGP en objets.
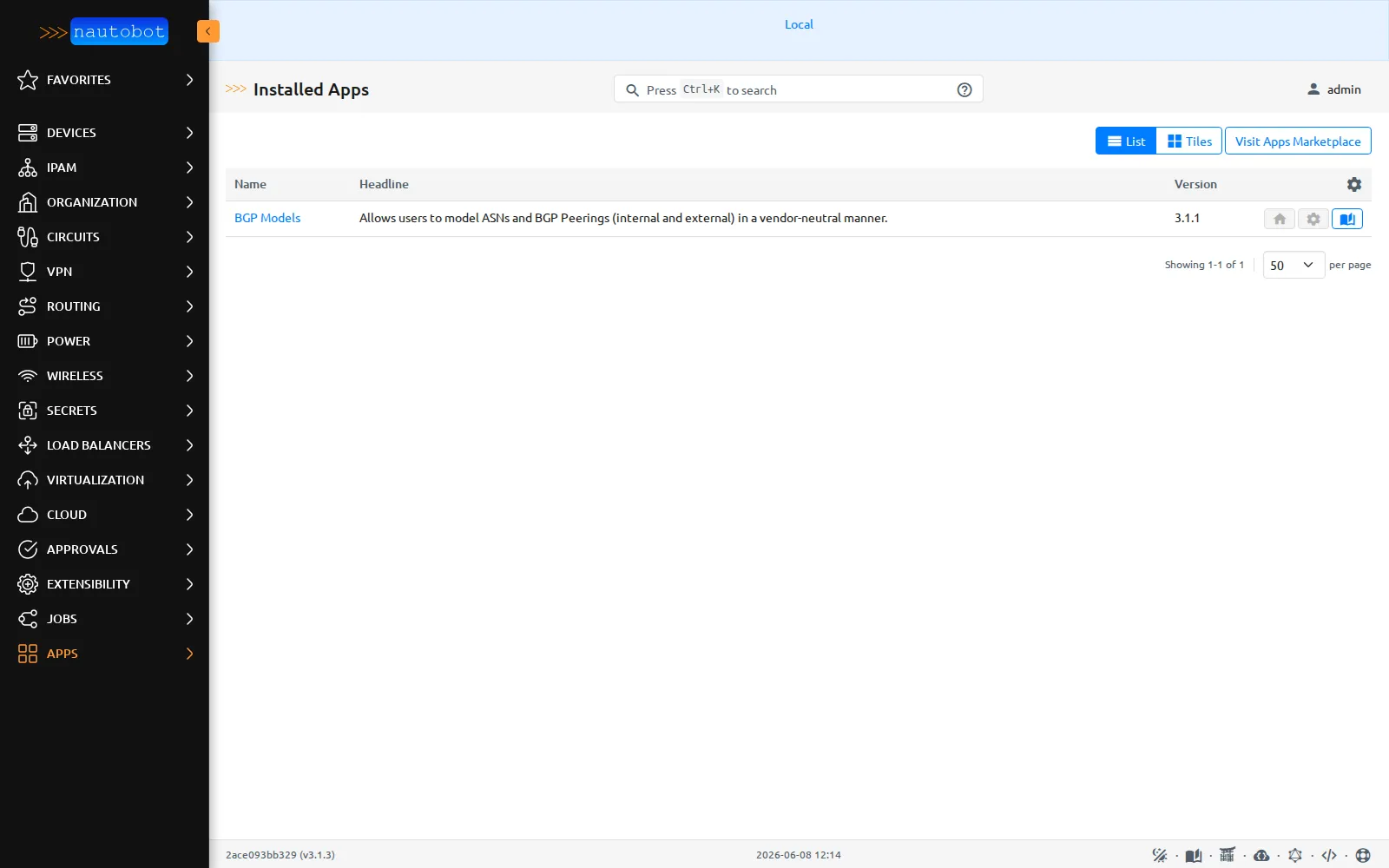 La page Installed Apps de Nautobot : une app installée, BGP Models 3.1.1, décrite « Allows users to model ASNs and BGP Peerings (internal and external) in a vendor-neutral manner. ». L’écosystème d’apps se gère depuis cette page.
La page Installed Apps de Nautobot : une app installée, BGP Models 3.1.1, décrite « Allows users to model ASNs and BGP Peerings (internal and external) in a vendor-neutral manner. ». L’écosystème d’apps se gère depuis cette page.
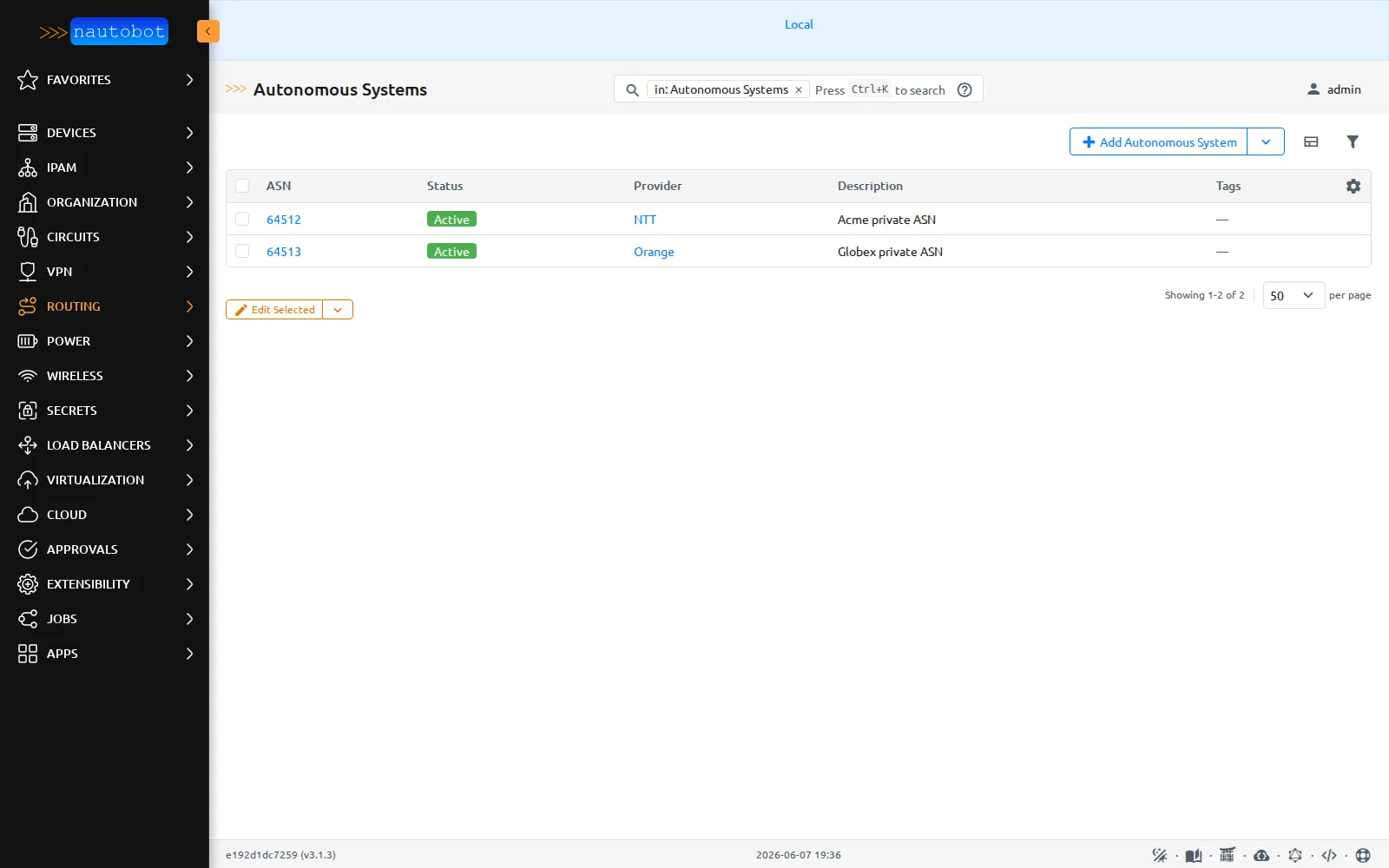 Avec BGP Models, les systèmes autonomes (
Avec BGP Models, les systèmes autonomes (AS 64512, AS 64513) sont des objets de première classe. Le cœur de NetBox, lui, ne modélise pas le BGP.
Une précision honnête, parce qu’elle est facile à mal lire : NetBox aussi a un système de plugins, dont Nautobot a d’ailleurs hérité, et un plugin BGP existe également côté NetBox. Étendre le modèle par plugin n’est donc pas une exclusivité de Nautobot. Ce que montre le lab, c’est un contraste de cœur : le BGP n’est pas dans le cœur de NetBox, alors qu’ici Nautobot le porte via une app installée. Structurer le BGP en objets reste, des deux côtés, une affaire de plugin à ajouter.
Le revers vaut pour les deux : chaque app ou plugin est une dépendance de plus à installer, faire tourner et maintenir. La puissance d’extension est réelle, son coût aussi.
La couche data : custom fields, computed fields, config context
Nautobot reprend les deux mécanismes de NetBox pour porter l’intention au-delà du modèle, et en ajoute un troisième qui lui est propre.
Les deux repris : les custom fields (champs typés stockés) et le config context (intention JSON fusionnée). Sur le lab, par1-leaf1 porte les mêmes custom fields criticality et monitoring_id, et le même config context SNMP / NTP / BGP.
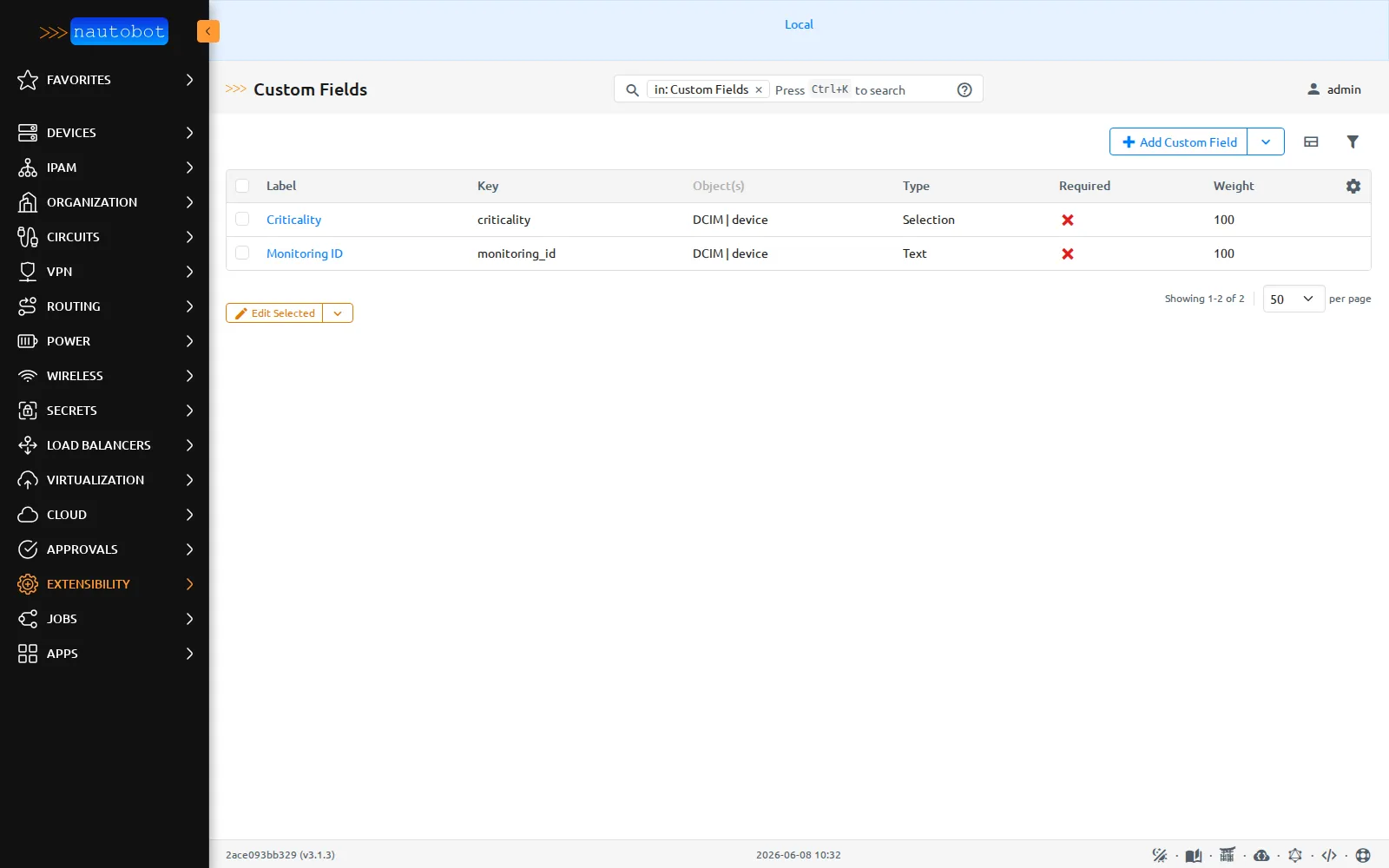 Les mêmes deux champs que côté NetBox, ici clés
Les mêmes deux champs que côté NetBox, ici clés criticality (Selection) et monitoring_id (Text), liés au content type DCIM | device.
Le troisième mécanisme, absent de NetBox : les computed fields. Ce sont des champs dérivés, dont la valeur est calculée par un template au moment du rendu, jamais stockée. Sur le lab, un computed field mgmt_name au template {{ obj.name }}-mgmt produit, sur par1-leaf1, la valeur par1-leaf1-mgmt.
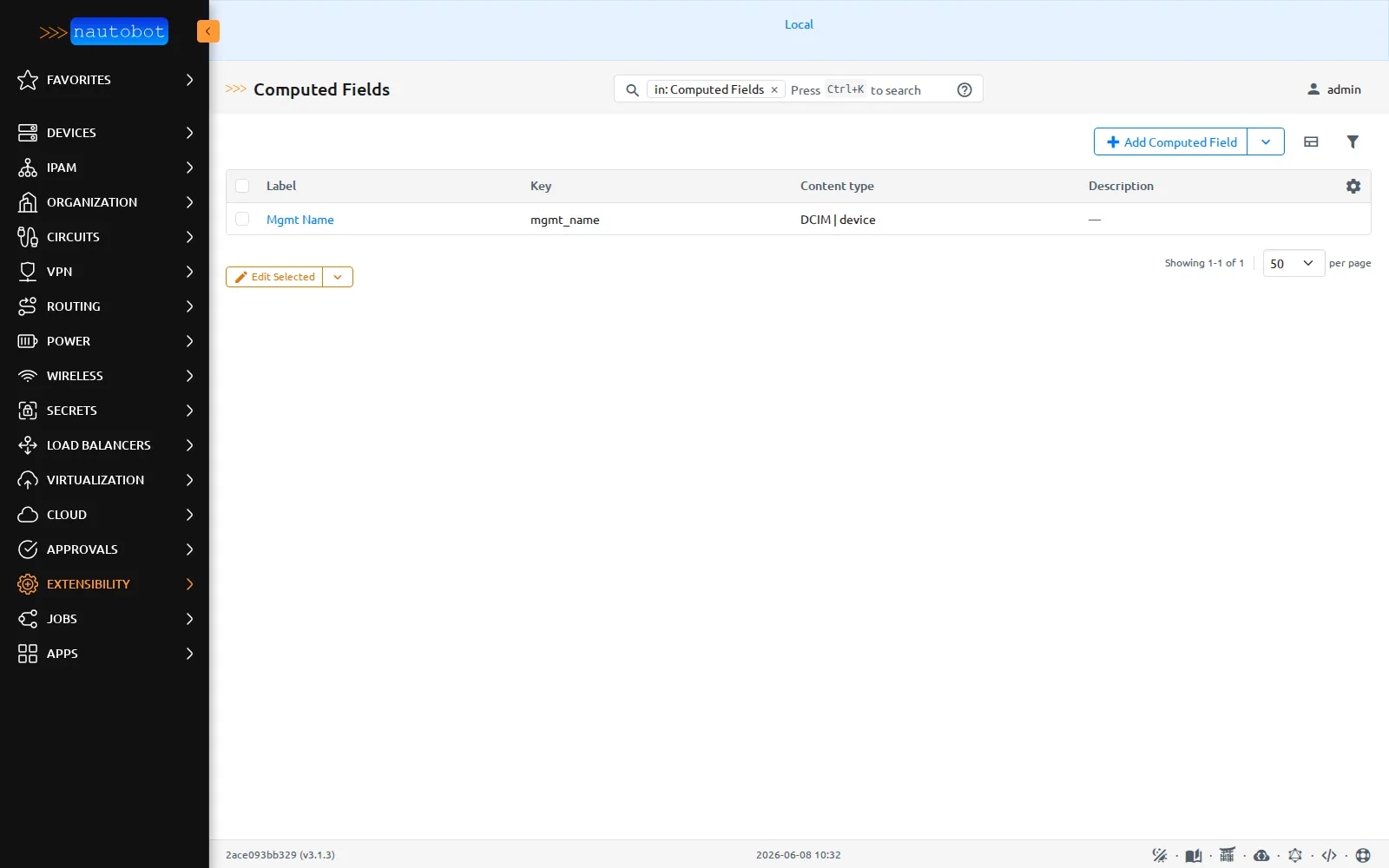 Un champ calculé,
Un champ calculé, Mgmt Name (clé mgmt_name), sur le content type DCIM | device. NetBox n’a pas cette page : la fonctionnalité est propre à Nautobot.
Sur la fiche du device, les deux familles cohabitent, les Custom Fields stockés et le Computed Field recalculé :
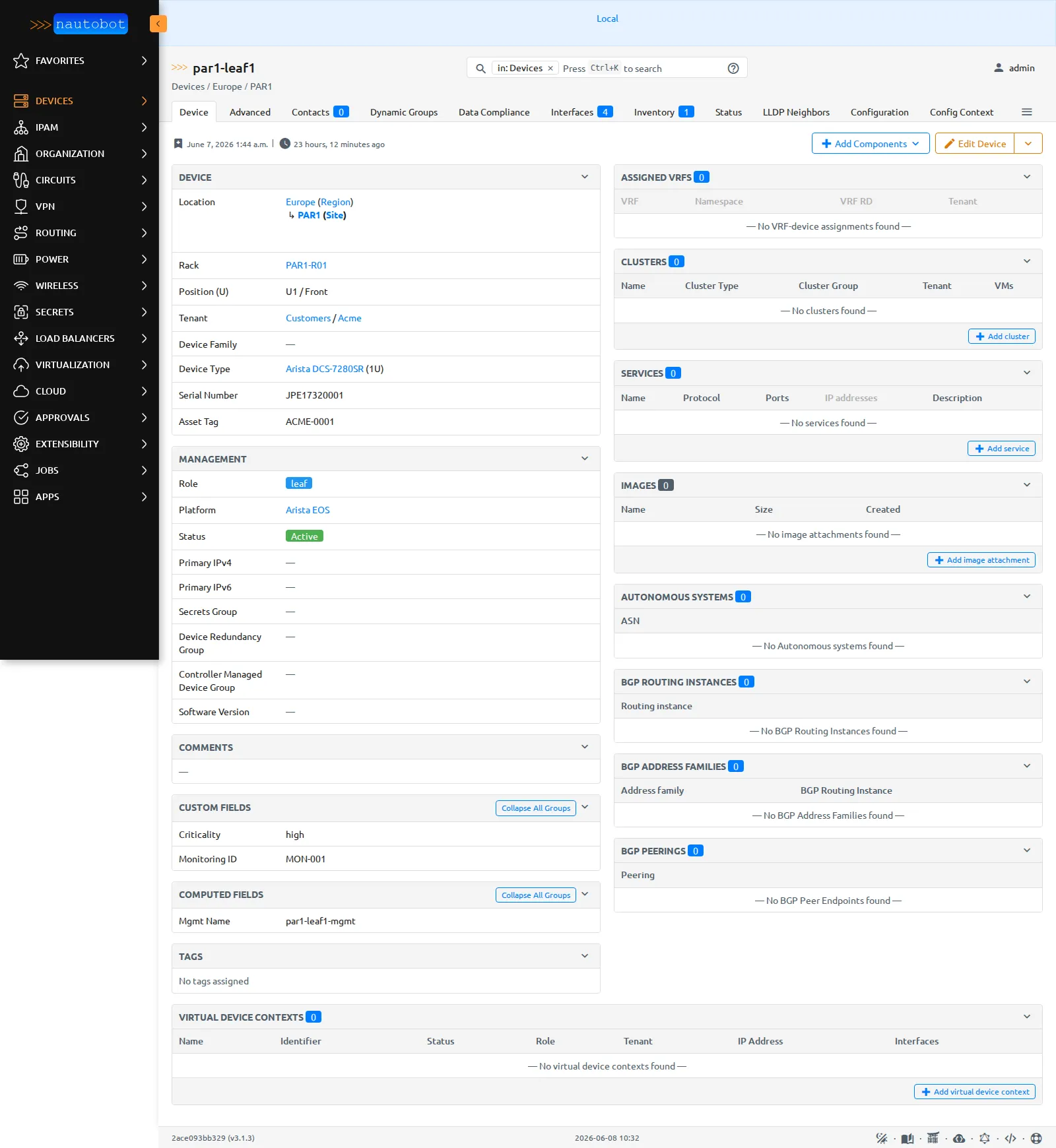 Sur
Sur par1-leaf1 : les Custom Fields Criticality = high et Monitoring ID = MON-001 (stockés), et le Computed Field Mgmt Name = par1-leaf1-mgmt (recalculé à chaque rendu).
Deux pièges, par contre. D’abord le config context : Nautobot ne renvoie que le contexte local par défaut, le merge rendu demandant un ?include=config_context ; NetBox, lui, donne le merge d’emblée. Un détail d’API, mais qui change un mapping de synchro, on le verra à l’article de migration.
Ensuite, et c’est cohérent avec la thèse de l’article : un computed field dérive une valeur au rendu, mais un Job (ou un Generator) Nautobot peut aller plus loin, calculer cette donnée au plus près de la base et même agir dessus. La frontière entre « champ dérivé » et « automatisation » devient poreuse, et c’est exactement l’intérêt d’avoir l’automatisation dans la SoT.
Un Job, pour de vrai
Passons au Job. Un Job Nautobot, c’est une classe Python avec une méthode run(). Celui-ci est volontairement minimal et en lecture seule : il liste les devices avec leur rôle et leur location, puis compte par rôle. Il n’écrit rien.
from collections import Counter
from nautobot.apps.jobs import Job, register_jobs
from nautobot.dcim.models import Device
class DeviceRoleAudit(Job):
class Meta:
name = "Device Role Audit (read-only)"
description = "List devices with their role and location, count by role. No writes."
def run(self):
counts = Counter()
for d in Device.objects.all().order_by("name"):
role = d.role.name if d.role else "-"
location = d.location.name if d.location else "-"
counts[role] += 1
self.logger.info("%s | role=%s | location=%s | id=%s", d.name, role, location, d.id)
for role, n in sorted(counts.items()):
self.logger.success("role '%s': %d device(s)", role, n)
self.logger.info("Total devices audited: %d", sum(counts.values()))
register_jobs(DeviceRoleAudit)
Le détail qui porte toute la thèse : Device.objects.all(). C’est l’ORM de Nautobot, un accès direct à la base, sans HTTP ni client API. Le code tourne là où vit la donnée. Une fois le fichier déposé et le Job activé, on l’exécute. Sortie réelle, capturée telle quelle sur le lab :
$ nautobot-server runjob --local -u admin sot_audit.DeviceRoleAudit
info: lon1-leaf1 | role=leaf | location=LON1 | id=2d6b8478-6260-4c21-b247-f2ad5ee65425
info: par1-leaf1 | role=leaf | location=PAR1 | id=a5b788f0-1635-4881-8017-ff736ba72068
info: par1-pp1 | role=patch-panel | location=PAR1 | id=17bceb95-2601-41e3-bcd6-7a4da36cf04f
info: par1-spine1 | role=spine | location=PAR1 | id=0c1213a8-6bb1-44fa-af5b-920fc196c95b
success: role 'leaf': 2 device(s)
success: role 'patch-panel': 1 device(s)
success: role 'spine': 1 device(s)
info: Total devices audited: 4
[23:53:02] sot_audit.DeviceRoleAudit: SUCCESS
[23:53:02] sot_audit.DeviceRoleAudit: Duration 0 minutes, 0.09 seconds
Le résultat n’est pas qu’une sortie console : Nautobot conserve le Job, son exécution et ses logs comme des objets, avec leur historique.
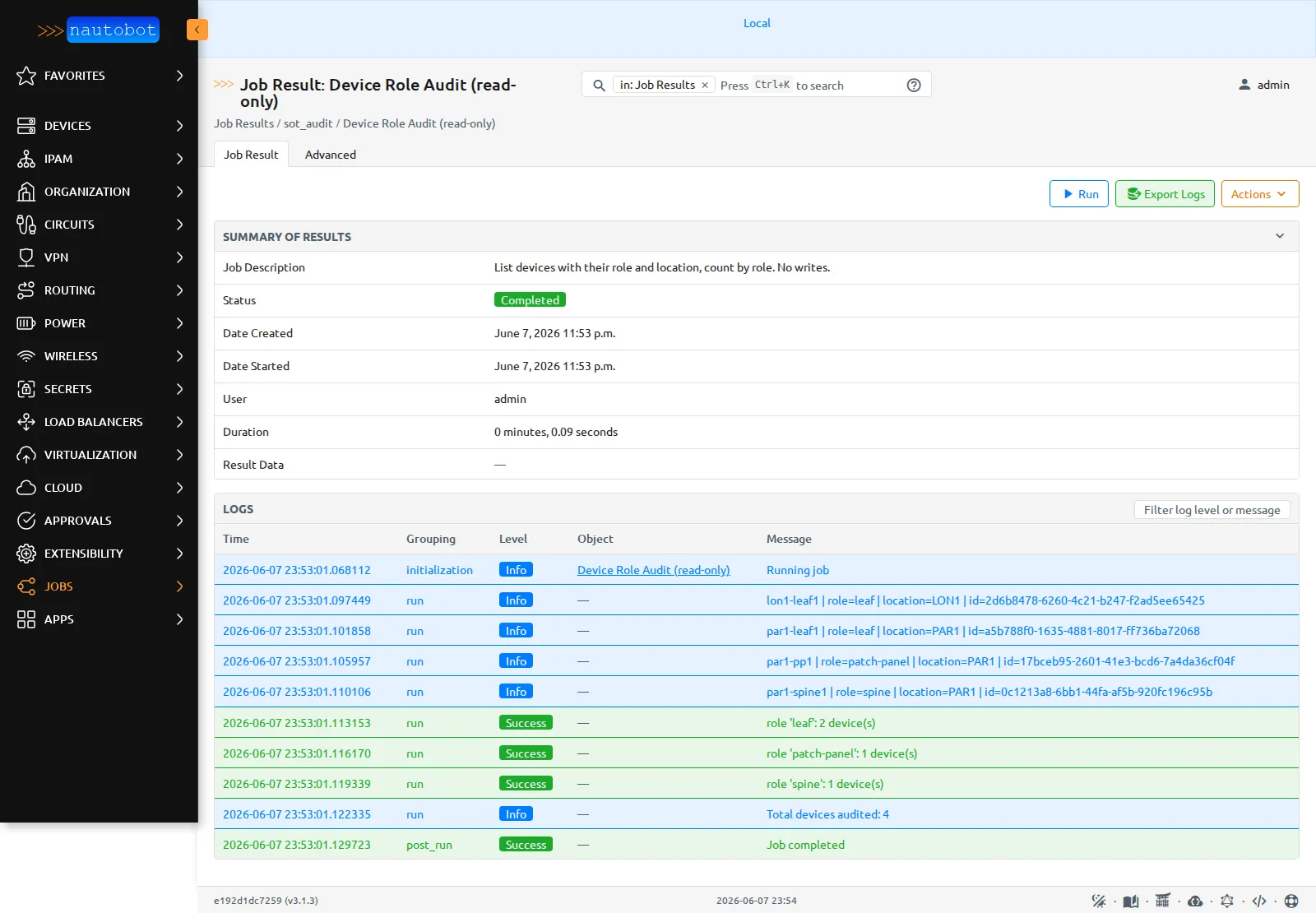 Le JobResult : statut Completed en 0,09 s, et un journal structuré qui liste chaque device (rôle, location, UUID) puis le comptage par rôle (
Le JobResult : statut Completed en 0,09 s, et un journal structuré qui liste chaque device (rôle, location, UUID) puis le comptage par rôle (leaf 2, patch-panel 1, spine 1, total 4). Du code d’automatisation qui vit dans la SoT, tracé et rejouable.
L’audit est trivial, mais le pattern ne l’est pas : remplacer la boucle de lecture par une vérification de conformité, un calcul d’allocation IP ou une génération de données, et on tient une brique d’automatisation qui s’exécute au plus près de la donnée, avec permissions, logs et planification fournis par la plateforme.
Python ou Ansible ?
Reste une nuance qu’il serait malhonnête d’éluder. Mettre des Jobs Python dans la SoT ne rend pas Ansible obsolète, et ce n’est pas une question de langage « plus rapide ».
Ce qui change, c’est où s’exécute la logique. Un Job dans Nautobot lit la donnée localement, sans l’aller-retour réseau d’un orchestrateur externe qui requête l’API en boucle. Sur de gros inventaires, éviter ces allers-retours compte. Mais Ansible garde des atouts solides : l’idempotence déclarative, des modules réseau prêts à l’emploi, une lisibilité que tout le monde partage, et le push de configuration multi-vendor que Nautobot ne fait pas. Les deux ne jouent d’ailleurs pas le même rôle : Nautobot raisonne et structure la donnée, Ansible pousse la configuration sur les équipements.
C’est un compromis selon le contexte, pas un classement. Et sans benchmark réel, aucun chiffre de performance ne tiendrait ici.
Vers une SoT versionnée
Nautobot durcit le modèle et déplace l’automatisation dans la SoT. Il reste pourtant une chose qu’il ne fait pas, comme NetBox : il vit sur un état unique. Modifier l’inventaire, c’est modifier l’état courant. Pas de branche pour préparer un changement à l’écart, pas de revue façon pull request avant de l’appliquer, pas de merge.
C’est précisément ce qu’ajoute l’article Infrahub de la série : une Source of Truth versionnée et branchable, où un changement vit dans une branche, se révise, puis se merge, avec un historique complet. Migrer cette infra de Nautobot vers Infrahub fait justement l’objet du dernier article.
À retenir
- Nautobot est un fork de NetBox qui a divergé : même origine, mais un modèle v2 repensé et un pari différent sur l’automatisation.
- Le modèle est plus strict : statuts et rôles deviennent des objets typés par contenu, les identifiants sont des UUID, les emplacements sont des locations hiérarchiques, l’IPAM gagne des namespaces.
- L’automatisation entre dans la SoT : les Jobs sont du Python qui tourne dans Nautobot, avec accès direct à l’ORM. On l’a vu sur un Job réel, exécuté et tracé.
- Ce n’est pas Python contre Ansible : c’est exécuter la logique au plus près de la donnée plutôt que la piloter de loin. Chacun garde son terrain.
- Il manque encore le versioning : Nautobot vit sur un état unique, sans branche ni merge. C’est le sujet de l’article Infrahub.
Pour aller plus loin
- L’article précédent, la fondation : NetBox, la Source of Truth d’origine.
- La suite de la série : Infrahub, une SoT modélisée comme un graphe typé et versionnée, puis la comparaison des trois et la migration avec infrahub-sync (article à venir).
Dépôt du projet : nautobot/nautobot