Infrahub (OpsMill) prend le problème de la Source of Truth (SoT) par un autre bout que NetBox ou Nautobot : tout y est un graphe typé qu’on définit soi-même, et la donnée se versionne comme du code, avec des branches, une revue et un merge. On édite le réseau comme un schéma, qu’on révise en pull request avant de l’appliquer.
Toute la série s’appuie sur le même petit lab, pour comparer ce qui est comparable : un fabric Spine/Leaf minimal réparti sur deux sites.
 Le lab de la série : 4 devices sur deux sites (PAR1 chez Acme, LON1 chez Globex), un patch panel dans le chemin de câblage de PAR1, des circuits entre les sites, un underlay BGP (AS 64512 et 64513) et un overlay en VRF CUSTOMER-A. C’est cette même architecture que chaque Source of Truth de la série va modéliser.
Le lab de la série : 4 devices sur deux sites (PAR1 chez Acme, LON1 chez Globex), un patch panel dans le chemin de câblage de PAR1, des circuits entre les sites, un underlay BGP (AS 64512 et 64513) et un overlay en VRF CUSTOMER-A. C’est cette même architecture que chaque Source of Truth de la série va modéliser.
Troisième article de la série Source of Truth : la même architecture, cette fois modélisée par Infrahub. NetBox et Nautobot la modélisent dans les articles précédents, et un quatrième compare les trois et migre l’infra de l’une à l’autre avec infrahub-sync. Sur le lab, Infrahub porte déjà cette archi (on verra dans le dernier article comment l’y migrer ; ici, on regarde le résultat modélisé).
Tout est un kind du schéma
NetBox et Nautobot offrent un modèle prédéfini qu’on étend à la marge. Infrahub part d’un schéma que l’on définit soi-même : des kinds (des types d’objets), chacun avec ses attributs typés et ses relations. Le schéma du lab en compte 150 au total ; le namespace Infra, celui qui modélise notre réseau, en regroupe l’essentiel.
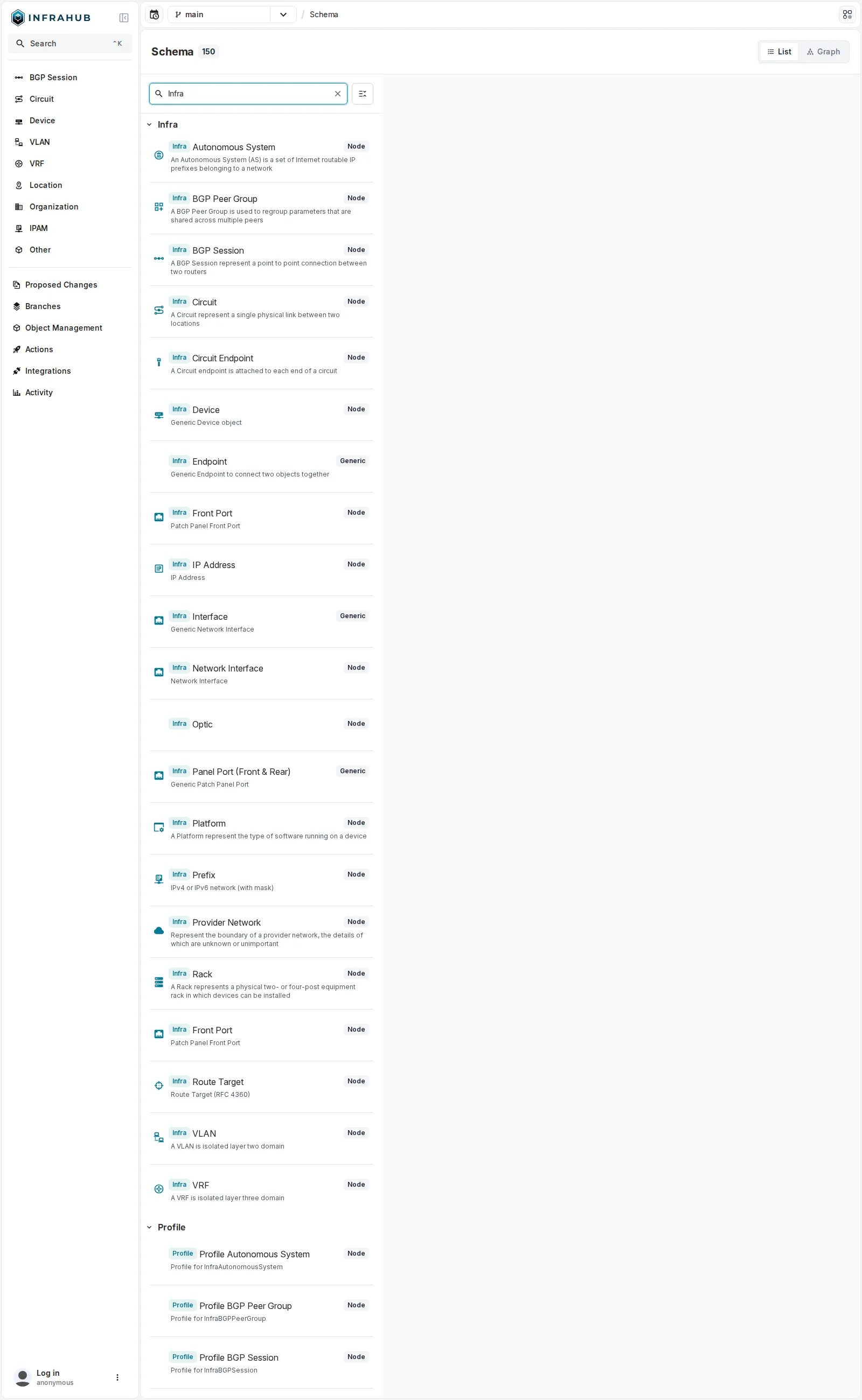 La vue Schema d’Infrahub (150 kinds au total), filtrée sur le namespace
La vue Schema d’Infrahub (150 kinds au total), filtrée sur le namespace Infra : Device, Network Interface, IP Address, Prefix, VRF, VLAN, Circuit, Autonomous System, BGP Session, BGP Peer Group, Optic, Rack, Platform… Chaque kind est typé Node ou Generic.
Différence nette avec les deux autres SoT : le BGP n’est ni un plugin ni une app, c’est un ensemble de kinds du schéma (InfraAutonomousSystem, InfraBGPSession, InfraBGPPeerGroup) reliés aux devices. Modéliser, chez Infrahub, c’est éditer le schéma, pas installer une extension.
La même archi, en objets typés
Les 4 devices du lab sont des objets du kind InfraDevice.
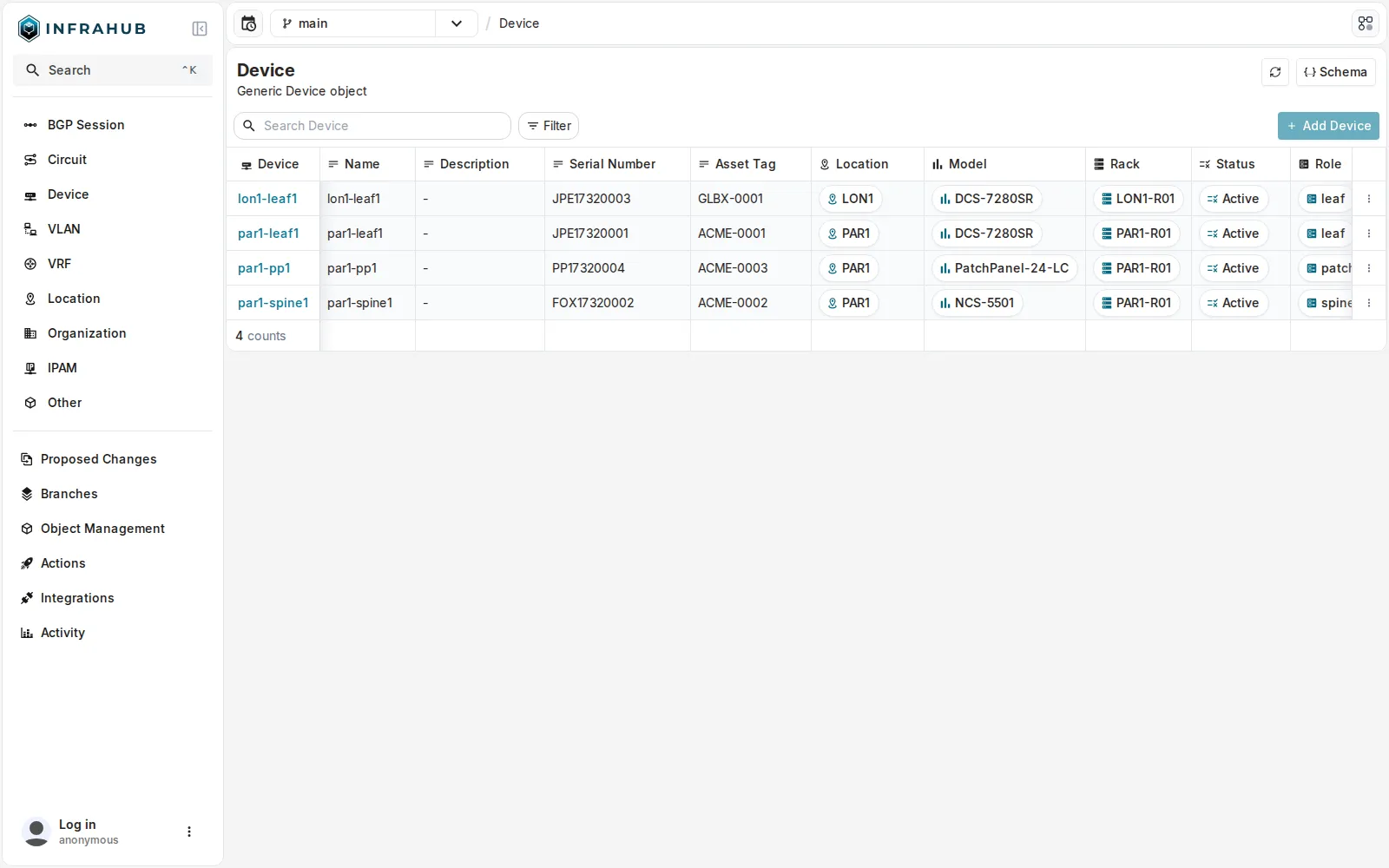 Les 4 devices de l’archi (
Les 4 devices de l’archi (lon1-leaf1, par1-leaf1, par1-pp1, par1-spine1) comme objets InfraDevice : location, model, rack, role et status renseignés.
Chaque kind déclare explicitement ses attributs (des valeurs typées) et ses relations (des liens typés vers d’autres kinds). Sur InfraDevice :
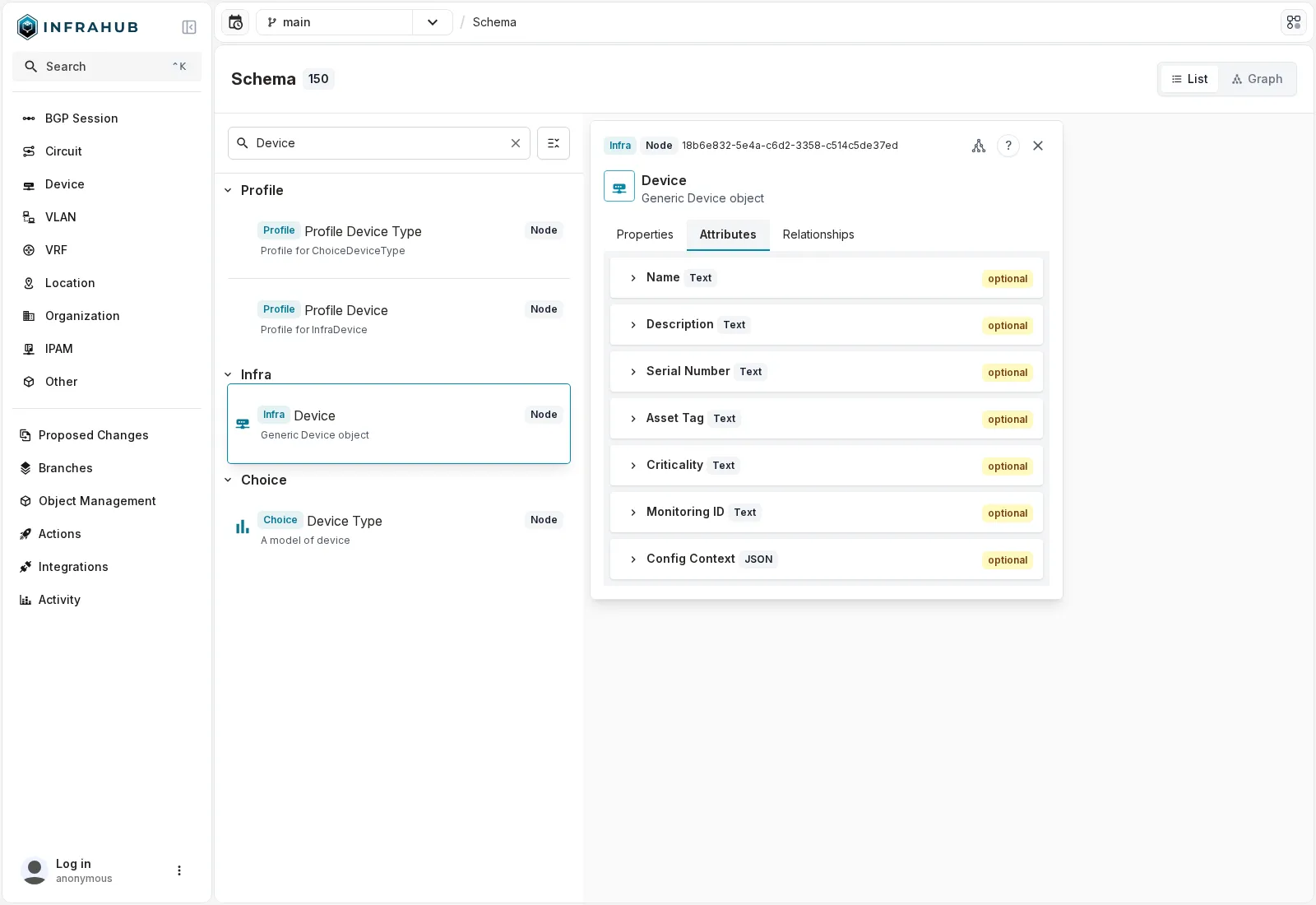 Les attributs du kind
Les attributs du kind InfraDevice : Name, Description, Serial Number, Asset Tag, et les trois ajoutés pour la couche data (Criticality, Monitoring ID en Text, Config Context en JSON). Chaque attribut a un kind explicite.
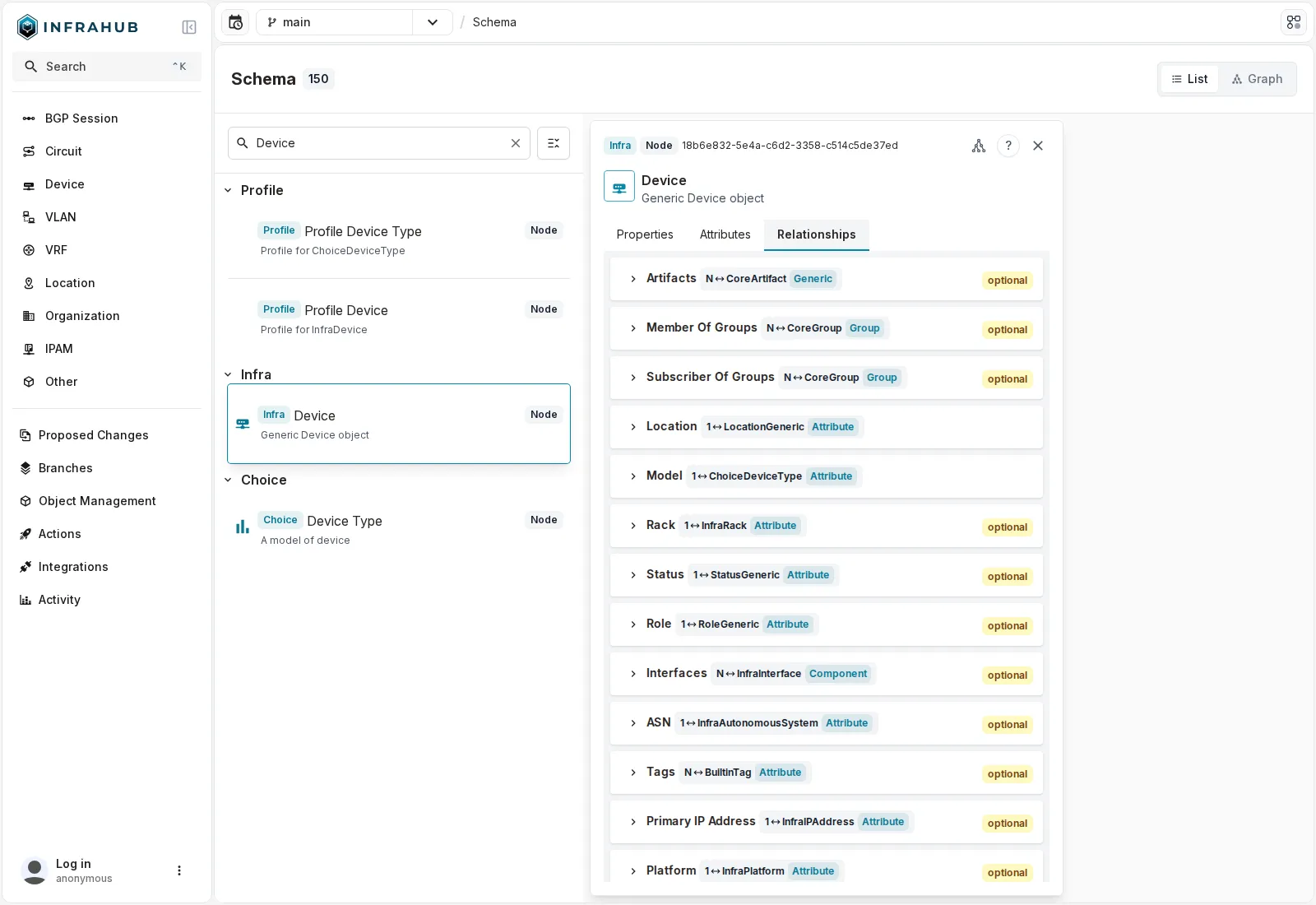 Les relations d’
Les relations d’InfraDevice, avec leur cardinalité (1 ou N) et leur nature (Attribute, Component…) : Location, Model, Rack, Status, Role, Interfaces, et ASN → InfraAutonomousSystem. Le BGP est une relation du schéma, pas un plugin.
La relation asn → InfraAutonomousSystem en est un bon exemple : l’AS d’un device est un objet à part entière, pas un champ texte. On remonte du device à son AS en une traversée, sans jointure à la main.
La couche data, déclarée dans le schéma
On l’a vu sur les attributs d’InfraDevice : la couche data (celle qui, dans NetBox et Nautobot, vit dans les custom fields et le config context) se déclare ici comme des attributs typés du schéma. Criticality et Monitoring ID sont des attributs Text, Config Context un attribut JSON. Sur un device, ça donne :
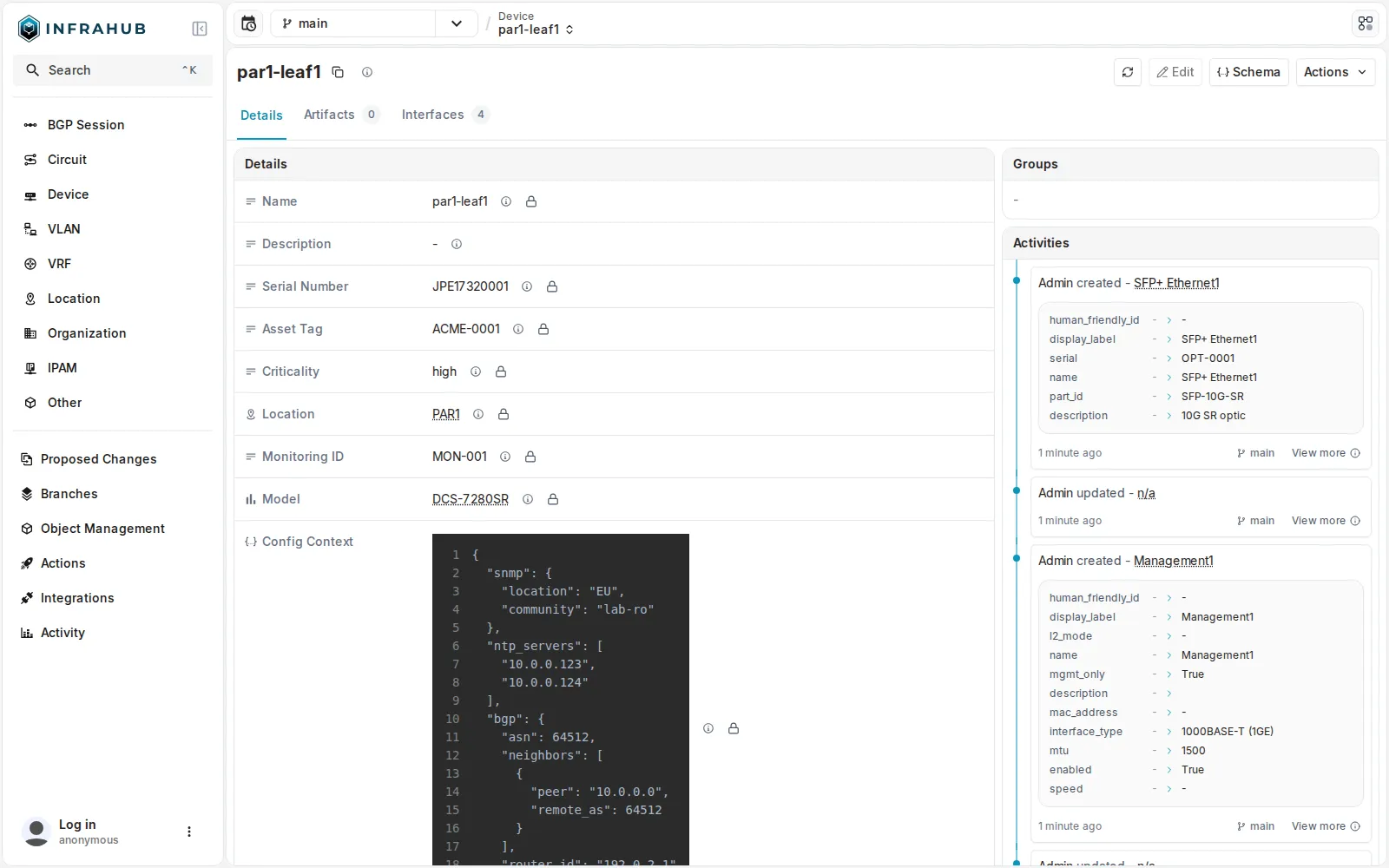 La fiche d’un device dans Infrahub : les custom fields (
La fiche d’un device dans Infrahub : les custom fields (Criticality, Monitoring ID) et le Config Context (le JSON snmp + ntp_servers + bgp) sont des attributs de l’objet, pas une couche à part.
Une nuance honnête sur la parité avec Nautobot : Infrahub connaît aussi les computed attributes, des attributs dont la valeur est calculée, l’équivalent des computed fields Nautobot. Le schéma de ce lab n’en définit aucun (vérifié par l’API) : c’est une capacité disponible, à activer si besoin, qu’on ne montre donc pas ici.
Un schéma qui s’étend
Comme tout est schéma, l’étendre est l’opération de base. Deux gestes suffisent : ajouter un attribut à un kind existant, ou créer un kind neuf. Le lab a fait les deux pour rapatrier ce que le modèle standard ne couvrait pas (les custom fields ci-dessus, et un kind InfraOptic pour les optiques) :
nodes: # un kind tout neuf
- name: Optic # devient le kind InfraOptic
namespace: Infra
attributes:
- { name: name, kind: Text }
- { name: serial, kind: Text, optional: true }
relationships:
- { name: device, peer: InfraDevice, cardinality: one, kind: Attribute }
extensions:
nodes: # étendre un kind existant
- kind: InfraDevice
attributes:
- { name: criticality, kind: Text, optional: true }
- { name: config_context, kind: JSON, optional: true }
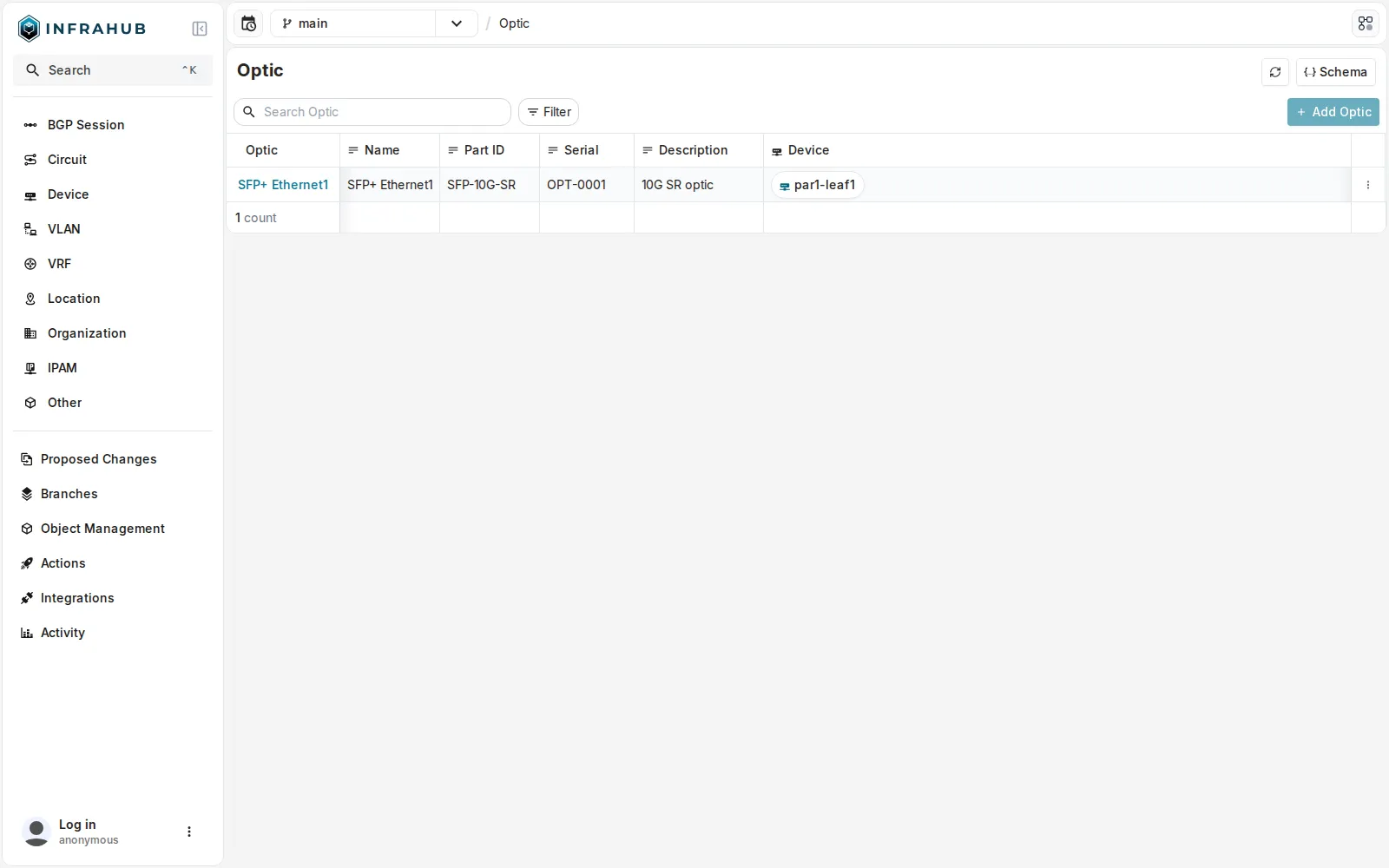 Le kind
Le kind InfraOptic, ajouté au schéma : l’optique SFP+ Ethernet1 (OPT-0001) devient un objet de première classe, rattaché à son device.
Le même mécanisme servira à la migration, pour plier le schéma à la forme de la donnée qu’on importe.
La signature : une Source of Truth versionnée et branchable
La vraie signature d’Infrahub, c’est que la donnée se versionne. On crée une branche, on y modifie le réseau à l’écart de main, puis on merge une fois la revue passée. Tout l’historique reste.
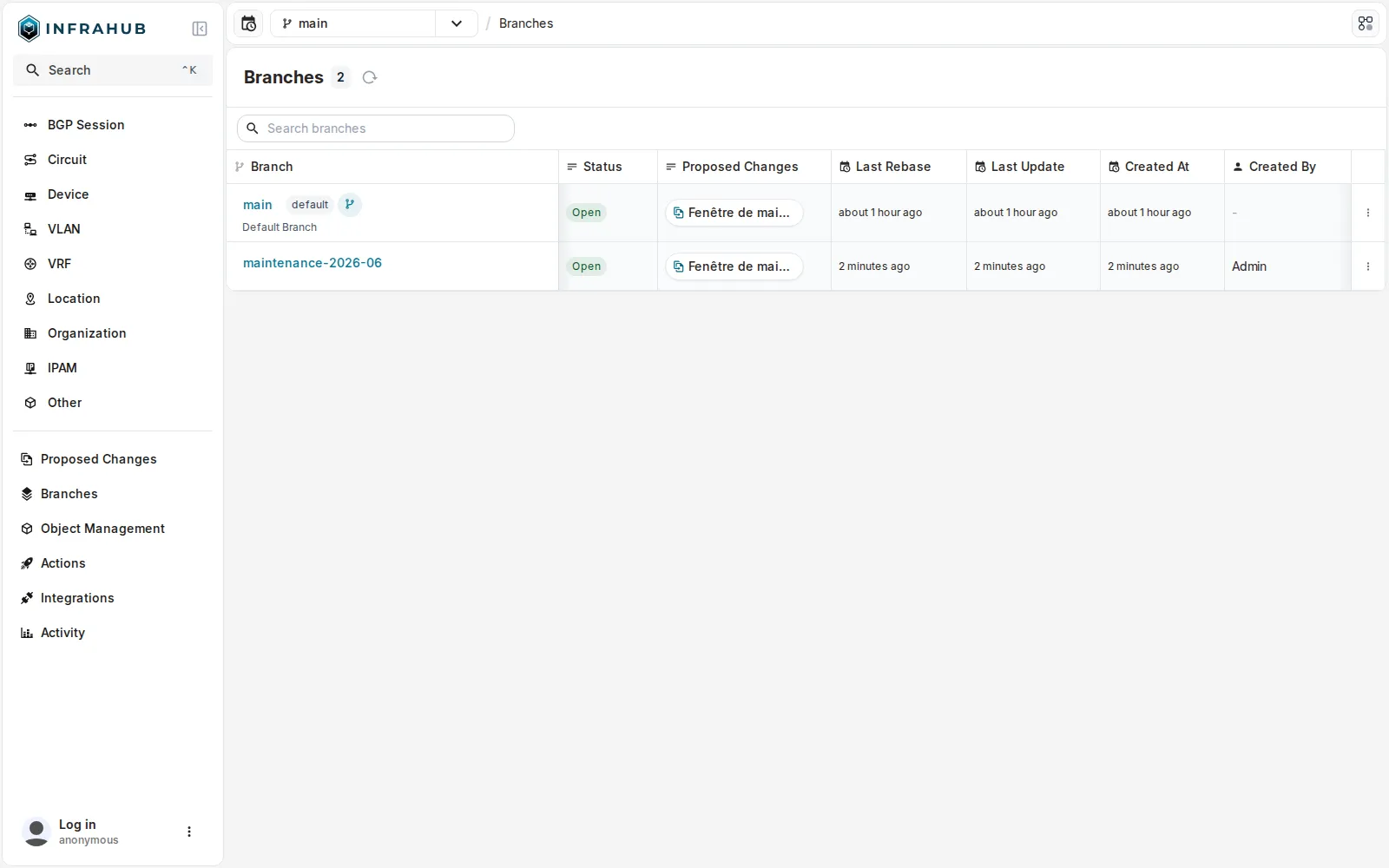 Les branches d’Infrahub :
Les branches d’Infrahub : main et une branche de travail. Modifier la SoT, c’est travailler sur une branche, comme du code.
Sur le lab, une branche maintenance-2026-06 modifie par1-leaf1 (sa description, sa criticité passée à critical) et ajoute une IP 10.0.0.250/32. La branche voit ces changements, main reste intact : 4 IP sur la branche, toujours 3 sur main. Le changement se révise comme une pull request, via une Proposed Change :
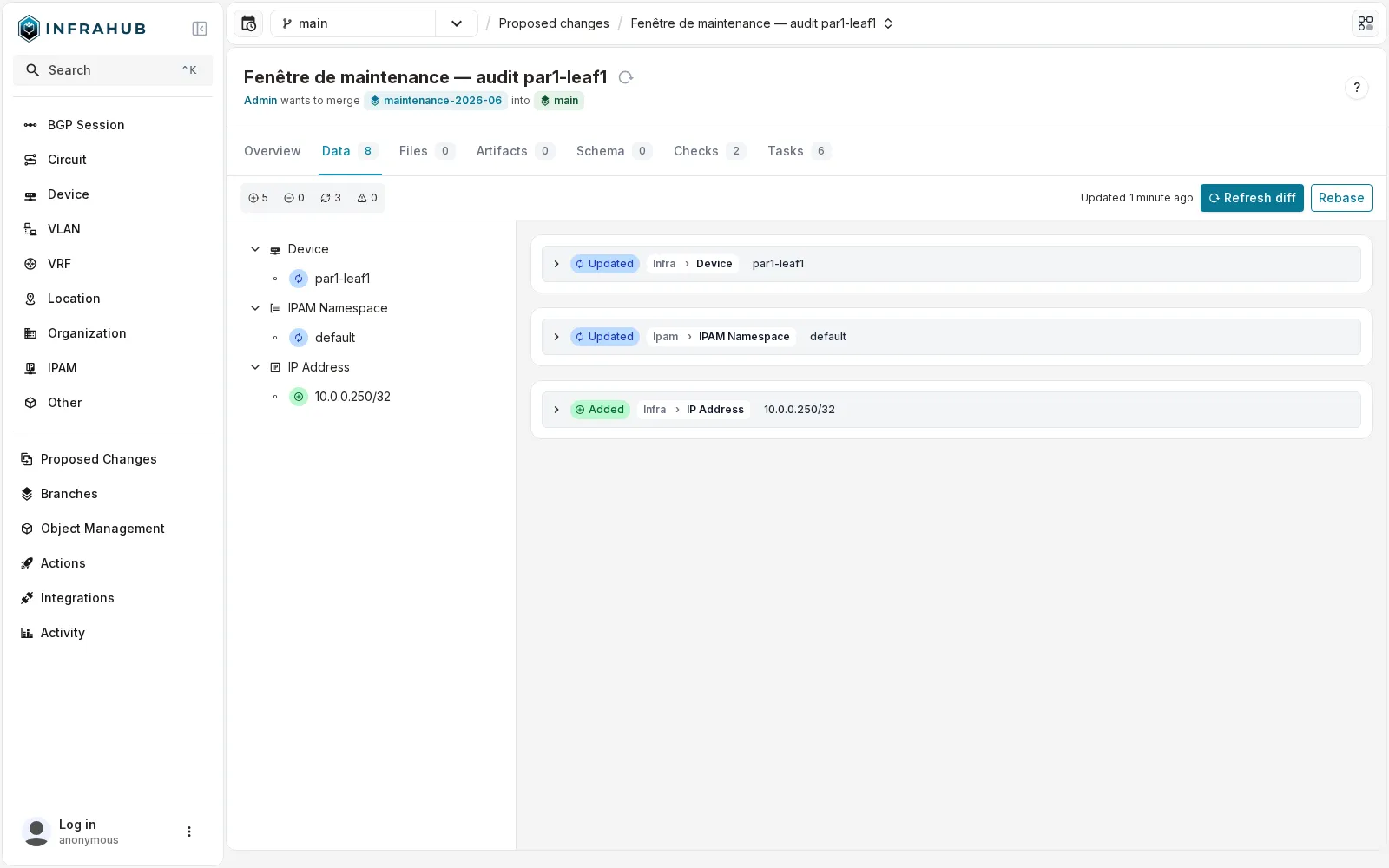 La Proposed Change montre exactement ce qui change avant le merge :
La Proposed Change montre exactement ce qui change avant le merge : par1-leaf1 mis à jour, l’IP 10.0.0.250/32 ajoutée. Ni NetBox ni Nautobot ne proposent cette revue : leur donnée n’a pas de branche à relire.
Une fois la Proposed Change validée, on merge la branche dans main : le changement arrive (le compteur d’IP passe de 3 à 4), la branche bascule au statut Merged, et l’historique du device trace toute la provenance.
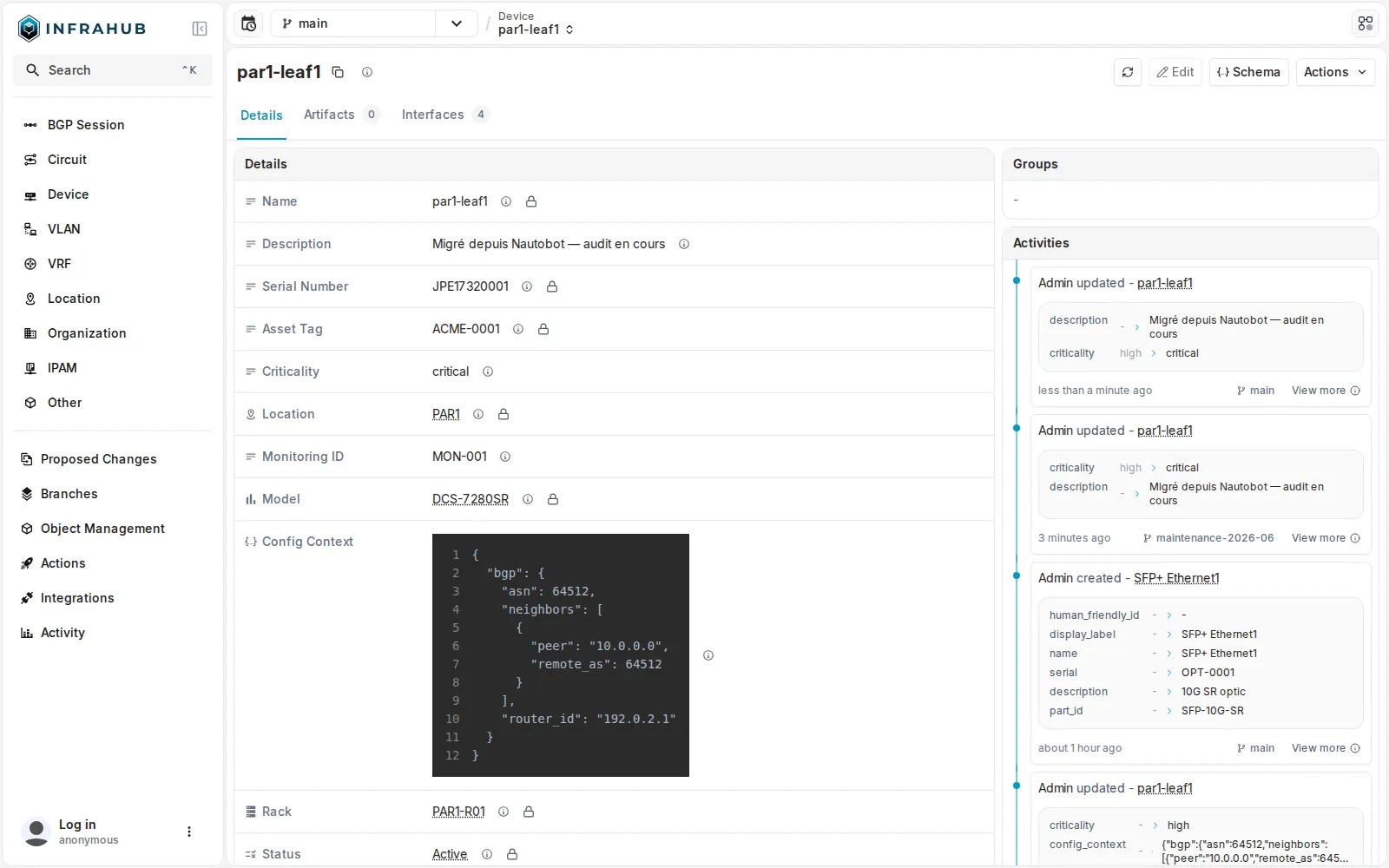 Après merge, la modification est sur
Après merge, la modification est sur main et l’audit-trail garde la trace complète : qui a changé quoi, sur quelle branche, et quand.
Et comme tout est un graphe typé, on l’interroge d’un bout à l’autre en GraphQL. Une seule requête remonte une optique vers son device, sa location et son modèle :
{
InfraOptic {
count
edges {
node {
name { value }
serial { value }
device {
node {
name { value }
location { node { name { value } } }
model { node { name { value } } }
}
}
}
}
}
}
La réponse renvoie en une requête l’optique SFP+ Ethernet1 (serial OPT-0001), son device par1-leaf1, sa location PAR1 et son modèle DCS-7280SR.
 L’explorer GraphQL d’Infrahub : un graphe typé se parcourt en une requête, de l’optique au device, à sa location et son modèle.
L’explorer GraphQL d’Infrahub : un graphe typé se parcourt en une requête, de l’optique au device, à sa location et son modèle.
À retenir
- Infrahub modélise tout comme un schéma typé (kinds, attributs, relations) qu’on définit et qu’on édite, là où NetBox et Nautobot offrent un modèle prédéfini.
- Le BGP, les optiques, la couche data (custom fields, config context) sont des kinds et des attributs du schéma, pas des plugins ni une couche à part.
- Sa signature, le versioning : la SoT se modifie dans une branche, se révise par Proposed Change, puis se merge avec un audit-trail. Aucune des deux autres SoT ne le fait nativement.
- Tout est un graphe requêtable en GraphQL d’un bout à l’autre.
Pour aller plus loin
- Les autres Source of Truth de la série : NetBox, la Source of Truth d’origine et Nautobot, mettre l’automatisation dans la Source of Truth.
- Le dernier article comparera les trois et migrera cette infra d’une SoT à l’autre : Trois Source of Truth comparées, et la migration avec infrahub-sync (à venir).
Dépôt du projet : opsmill/infrahub